Multitasking Management in the Operating System Kernel
Open SourceAs tasks share time on one processor kernel, I had to deal with multitasking management. Or rather pseudo-multitasking as tasks share time at one processor kernel. At first I’ll try to tell about the types of multitasking (cooperative and preemptive). Then I’ll move on to scheduling principles for the preemptive multitasking. The article is optimized for first-readers who want to understand how multitasking operates at the kernel level. But as everything will be accompanied with examples which can be compiled and run, it may interest the ones who are familiar with the theory, but have never “tasted” the scheduler.
Introduction
To begin with, let’s define what “multitasking” means. Here’s the definition from the Wikipedia: > In computing, multitasking is a method where multiple tasks, also known as processes, are performed during the same period of time. The tasks share common processing resources, such as a CPU and main memory. In the case of a computer with a single CPU, only one task is said to be running at any point in time, meaning that the CPU is actively executing instructions for that task. Multitasking solves the problem by scheduling which task may be the one running at any given time, and when another waiting task gets a turn. The act of reassigning a CPU from one task to another one is called a context switch.
In this definition the notions of resource sharing and scheduling are introduced. In this article I will dwell on the latter. I will tell about scheduling on the basis of threads.
 Thus, we need to introduce one more notion, let’s name it a scheduling thread. It’s a set of instructions with the definite sequencing, which is executed by the CPU during the program run. As I am referring to multitasking, of course, there can be several computing threads in the system. The thread, instructions of which processor is carrying out at the given moment, is called active. Since only one instruction can be executed at one processor kernel at one moment, only one thread can be active. The process of chosing the active computing thread is called scheduling. In its turn, the module which is in charge of the choice is called the scheduler.
Thus, we need to introduce one more notion, let’s name it a scheduling thread. It’s a set of instructions with the definite sequencing, which is executed by the CPU during the program run. As I am referring to multitasking, of course, there can be several computing threads in the system. The thread, instructions of which processor is carrying out at the given moment, is called active. Since only one instruction can be executed at one processor kernel at one moment, only one thread can be active. The process of chosing the active computing thread is called scheduling. In its turn, the module which is in charge of the choice is called the scheduler.
There are plenty different scheduling methods. Most of them can be divided between two major types:
- cooperative — the scheduler can’t take time from the computing thread until it gives it itself.
- preemptive — after the time slice expiry the scheduler chooses the next active thread. The thread can also give away the rest of the time slice.
Let’s consider the cooperative scheduling method at first, as it’s easy to implement.
Cooperative Scheduler
Cooperative scheduler under consideration is very simple. The given material is for beginners, so that it would be easier for them to understand the multitasking. The ones who have at least theoretical notion, can move on to “Preemptive scheduler” part.
Primary Cooperative Scheduler
Let’s suppose that we have several tasks, quite short in time, and we can call them one by one. We will form the task like a common function with some set of parameters. The scheduler will operate on the structures array for these functions. It will call the task-functions with the set-up parameters. Having performed all the necessary actions for the task, the function will return controlling to the main scheduler loop.
#include
#define TASK_COUNT 2
struct task {
void (*func)(void *);
void *data;
};
static struct task tasks[TASK_COUNT];
static void scheduler(void) {
int i;
for (i = 0; i < TASK_COUNT; i++) {
tasks[i].func(tasks[i].data);
}
}
static void worker(void *data) {
printf("%s\n", (char *) data);
}
static struct task *task_create(void (*func)(void *), void *data) {
static int i = 0;
tasks[i].func = func;
tasks[i].data = data;
return &tasks[i++];
}
int main(void) {
task_create(&worker, "First");
task_create(&worker, "Second");
scheduler();
return 0;
}
Output Results:
First Second
Graph CPU Usage:

Cooperative Scheduler on the Basis of Events
Of course, the mentioned above example is too primitive. Let’s introduce a capability to activate the definite task. For that we should add a flag to the task description structure. The flag will indicate whether the task is active or not. We will also need a small API to manage the activation.
#include
#define TASK_COUNT 2
struct task {
void (*func)(void *);
void *data;
int activated;
};
static struct task tasks[TASK_COUNT];
struct task_data {
char *str;
struct task *next_task;
};
static struct task *task_create(void (*func)(void *), void *data) {
static int i = 0;
tasks[i].func = func;
tasks[i].data = data;
return &tasks[i++];
}
static int task_activate(struct task *task, void *data) {
task->data = data;
task->activated = 1;
return 0;
}
static int task_run(struct task *task, void *data) {
task->activated = 0;
task->func(data);
return 0;
}
static void scheduler(void) {
int i;
int fl = 1;
while (fl) {
fl = 0;
for (i = 0; i < TASK_COUNT; i++) {
if (tasks[i].activated) {
fl = 1;
task_run(&tasks[i], tasks[i].data);
}
}
}
}
static void worker1(void *data) {
printf("%s\n", (char *) data);
}
static void worker2(void *data) {
struct task_data *task_data;
task_data = data;
printf("%s\n", task_data->str);
task_activate(task_data->next_task, "First activated");
}
int main(void) {
struct task *t1, *t2;
struct task_data task_data;
t1 = task_create(&worker1, "First create");
t2 = task_create(&worker2, "Second create");
task_data.next_task = t1;
task_data.str = "Second activated";
task_activate(t2, &task_data);
scheduler();
return 0;
}
Output Results:
Second activated First activated
Graph CPU Usage

Cooperative Scheduler on the Basis of the Message Queue
The problems of the above mentioned method are obvious. If someone wants to activate a task two times, until the task is handled, he won’t be able to do that. Information about the second activation is checked up. This problem can be partially solved with the help of the message queue. Let’s add an array instead of flags. It will contain message queues for each thread.
#include
#include
#define TASK_COUNT 2
struct message {
void *data;
struct message *next;
};
struct task {
void (*func)(void *);
struct message *first;
};
struct task_data {
char *str;
struct task *next_task;
};
static struct task tasks[TASK_COUNT];
static struct task *task_create(void (*func)(void *), void *data) {
static int i = 0;
tasks[i].func = func;
tasks[i].first = NULL;
return &tasks[i++];
}
static int task_activate(struct task *task, void *data) {
struct message *msg;
msg = malloc(sizeof(struct message));
msg->data = data;
msg->next = task->first;
task->first = msg;
return 0;
}
static int task_run(struct task *task, void *data) {
struct message *msg = data;
task->first = msg->next;
task->func(msg->data);
free(data);
return 0;
}
static void scheduler(void) {
int i;
int fl = 1;
struct message *msg;
while (fl) {
fl = 0;
for (i = 0; i < TASK_COUNT; i++) {
while (tasks[i].first) {
fl = 1;
msg = tasks[i].first;
task_run(&tasks[i], msg);
}
}
}
}
static void worker1(void *data) {
printf("%s\n", (char *) data);
}
static void worker2(void *data) {
struct task_data *task_data;
task_data = data;
printf("%s\n", task_data->str);
task_activate(task_data->next_task, "Message 1 to first");
task_activate(task_data->next_task, "Message 2 to first");
}
int main(void) {
struct task *t1, *t2;
struct task_data task_data;
t1 = task_create(&worker1, "First create");
t2 = task_create(&worker2, "Second create");
task_data.next_task = t1;
task_data.str = "Second activated";
task_activate(t2, &task_data);
scheduler();
return 0;
}
Results:
Second activated Message 2 to first Message 1 to first
Graph CPU Usage:

Cooperative Scheduler with Call Order Saving
Another problem of the previous examples is that the order of tasks activation isn’t saved. Each task is assigned with its own priority, which is not always good. In order to solve this problem you can create one more message queue and a monitoring program that will deal with it.
#include
#include
#define TASK_COUNT 2
struct task {
void (*func)(void *);
void *data;
struct task *next;
};
static struct task *first = NULL, *last = NULL;
static struct task *task_create(void (*func)(void *), void *data) {
struct task *task;
task = malloc(sizeof(struct task));
task->func = func;
task->data = data;
task->next = NULL;
if (last) {
last->next = task;
} else {
first = task;
}
last = task;
return task;
}
static int task_run(struct task *task, void *data) {
task->func(data);
free(task);
return 0;
}
static struct task *task_get_next(void) {
struct task *task = first;
if (!first) {
return task;
}
first = first->next;
if (first == NULL) {
last = NULL;
}
return task;
}
static void scheduler(void) {
struct task *task;
while ((task = task_get_next())) {
task_run(task, task->data);
}
}
static void worker2(void *data) {
printf("%s\n", (char *) data);
}
static void worker1(void *data) {
printf("%s\n", (char *) data);
task_create(worker2, "Second create");
task_create(worker2, "Second create again");
}
int main(void) {
struct task *t1;
t1 = task_create(&worker1, "First create");
scheduler();
return 0;
}
Work Results:
First create Second create Second create again
Graph CPU Usage:

Before we move on to the preemptive scheduler, I would like to add that it’s used in real systems as costs for task switching are minimal. This approach requires a special attention from the programmer. He should monitor that the tasks are not looped during performance.
Preemptive Scheduler
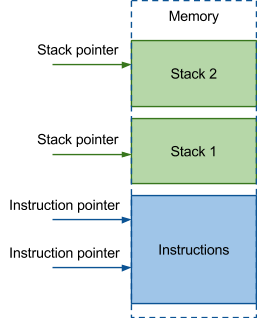 And now let’s imagine the following. There are two computing threads executing the same program. There is also a scheduler which can break an active thread, activate another one at any time before any instruction execution. To manage such tasks it’s not enough to have information about the thread call function and its parameters, as in case with cooperative schedulers. You should at least know the address of the current instruction being executed and the set of local variables for each task. Thus, you have to store copies of appropriate variables for each task. As local variables for threads are located on its walls, some space should be allocated for the stack of each thread. Somewhere should also be stored a pointer to the current location of the stack.
And now let’s imagine the following. There are two computing threads executing the same program. There is also a scheduler which can break an active thread, activate another one at any time before any instruction execution. To manage such tasks it’s not enough to have information about the thread call function and its parameters, as in case with cooperative schedulers. You should at least know the address of the current instruction being executed and the set of local variables for each task. Thus, you have to store copies of appropriate variables for each task. As local variables for threads are located on its walls, some space should be allocated for the stack of each thread. Somewhere should also be stored a pointer to the current location of the stack.
These data — instruction pointer и stack pointer — are stored in processor registers. Besides them other information is required for the proper work. This information is stored in the registers: state flags, different general purpose registers, in which temporary variables are stored, etc. All of this is called CPU context.
CPU context
 Processor context (CPU context) – is a data structure which stores internal state of processor registers. The context must allow bringing the processor into the proper state for computing thread execution. The process of one processor change to another is called a context switch.
Processor context (CPU context) – is a data structure which stores internal state of processor registers. The context must allow bringing the processor into the proper state for computing thread execution. The process of one processor change to another is called a context switch.
Description of the context structure for x86 architecture from our project.
struct context {
/* 0x00 */uint32_t eip; /**< instruction pointer */
/* 0x04 */uint32_t ebx; /**< base register */
/* 0x08 */uint32_t edi; /**< Destination index register */
/* 0x0c */uint32_t esi; /**< Source index register */
/* 0x10 */uint32_t ebp; /**< Stack pointer register */
/* 0x14 */uint32_t esp; /**< Stack Base pointer register */
/* 0x18 */uint32_t eflags; /**< EFLAGS register hold the state of the processor */
};
The notions of CPU context and context switch are the fundamentals in understanding the principle of preemptive scheduling.
Context switch
Context switch — is the change of one thread by another one. The scheduler saves the current context and uploads to processor registers another one. I have already mentioned before that the scheduler can break an active thread at any moment, which somewhat simplifies the pattern. But actually not the scheduler breaks the thread, but the current program is interrupted by the CPU as a consequence of response to an outside event — hardware interrupt — and passes control to the scheduler. For example, an outside event is a system timer, which counts the time slice for the active thread operation. If we assume that the system has only one source of interruption, the system timer, then processor time chart will look like the following:  Context switch procedure for x86 architecture:
Context switch procedure for x86 architecture:
.global context_switch
context_switch:
movl 0x04(%esp), %ecx /* Point ecx to previous registers */
movl (%esp), %eax /* Get return address */
movl %eax, CTX_X86_EIP(%ecx) /* Save it as eip */
movl %ebx, CTX_X86_EBX(%ecx) /* Save ebx */
movl %edi, CTX_X86_EDI(%ecx) /* Save edi */
movl %esi, CTX_X86_ESI(%ecx) /* Save esi */
movl %ebp, CTX_X86_EBP(%ecx) /* Save ebp */
add $4, %esp /* Move esp in state corresponding to eip */
movl %esp, CTX_X86_ESP(%ecx) /* Save esp */
pushf /* Push flags */
pop CTX_X86_EFLAGS(%ecx) /* ...and save them */
movl 0x04(%esp), %ecx /* Point ecx to next registers */
movl CTX_X86_EBX(%ecx), %ebx /* Restore ebx */
movl CTX_X86_EDI(%ecx), %edi /* Restore edi */
movl CTX_X86_ESP(%ecx), %esi /* Restore esp */
movl CTX_X86_EBP(%ecx), %ebp /* Restore ebp */
movl CTX_X86_ESP(%ecx), %esp /* Restore esp */
push CTX_X86_EFLAGS(%ecx) /* Push saved flags */
popf /* Restore flags */
movl CTX_X86_EIP(%ecx), %eax /* Get eip */
push %eax /* Restore it as return address */
ret
Thread State Machine
An important distinction of the thread structure in case with preemptive scheduler from the case with cooperative scheduler is the context occurrence. Let’s see what happens to the thread from the moment of its creation till its end.

- init state is in charge of the fact that the thread is created, but hasn’t been added to the queue. And exit indicates that the thread has completed its performance but hasn’t deallocated the memory.
- run state should also be obvious — the thread in this state is performed at the processor.
- ready state indicates that the thread isn’t being performed, but is waiting when the scheduler provides the time. It is in the queue of the scheduler.
But a thread has other possible states. It can give away a time slice while waiting for some event. For example, it can fall asleep for some time and then continue performance from the moment it fell asleep (e.g. sleep call). Thus, a thread can be in any states (ready-to-run, finishing, sleep, etc), while in case with the cooperative scheduler it was enough to have a flag of some task activity.
That’s how you can imagine a generic state machine:
 In the chart a new wait state has appeared. It notifies the scheduler that the thread fell asleep and until it wakes up, it doesn’t need processor time. Now let’s consider API control management in details and also deepen out knowledge of thread states.
In the chart a new wait state has appeared. It notifies the scheduler that the thread fell asleep and until it wakes up, it doesn’t need processor time. Now let’s consider API control management in details and also deepen out knowledge of thread states.
States Implementation
If you look at the states chart more attentively, you’ll see that init and wait have almost no differences. Both of them can go into ready state only, i.e. that they can notify the scheduler that they are ready to get the slice time. Thus init state is redundant.
Now let’s consider the exit state. It has its own peculiarities. It is specified to the scheduler in the exit function, which will be described below.
Thread exit can be performed in two ways. The first one – a thread finishes its main function and deallocates occupied resources, the second one – a thread takes charge of resources deallocation. In the second case a thread sees that the other thread will deallocate its resources, notifies him of termination and passes control to the scheduler. In the first case a thread deallocates resources and also passes control to the scheduler. After the scheduler gets the control, the thread should never resume operation. In both cases exit state has the same meaning – a thread in this state doesn’t want to get the time slice and it doesn’t need to be located into the scheduler queue. It doesn’t differ from wait state so you don’t have to create a separate state.
Thus, we have three more states. We will store these states in three separate fields. We could store it in one integer field, but this decision was made in order to simplify checks. So thread states are the following:
- active — began and is operating on the processor
- waiting — waiting for some event. It also interchanges init and exit states
- ready — is under the scheduler control. It’s in the queue of ready threads or started on the processor. This state is somewhat wider of the ready we can see at the picture. In most cases active and ready. Ready and waiting are orthogonal in theory, but there are specific transitional states when these rules are broken. I will tell you about such cases below.
Creation
Thread creation contains all the necessary initialization (thread_init function) and a feasible thread starting. During initialization memory for the stack is deallocated, processor context is defined, necessary flags and other primary notions are specified.
When creating a thread we work with the queue of ready ones, which scheduler uses at random time. So we must block the scheduler operating with the thread structure until all the structure is completely initialized. After initialization the thread is in waiting state, which, as we remember, is in charge of the initial state. After that, depending on the passed parameters, we either start the thread, or don’t. The thread start function is the function of awakening in the scheduler. It is described in details below. We will only state that this function places the thread into the scheduler queue and changes waiting state to ready. The code of thread_create and thread_init function is the following:
struct thread *thread_create(unsigned int flags, void *(*run)(void *), void *arg) {
int ret;
struct thread *t;
//…
/* below we are going work with thread instances and therefore we need to
* lock the scheduler (disable scheduling) to prevent the structure being
* corrupted
*/
sched_lock();
{
/* allocate memory */
if (!(t = thread_alloc())) {
t = err_ptr(ENOMEM);
goto out;
}
/* initialize internal thread structure */
thread_init(t, flags, run, arg);
//…
}
out:
sched_unlock();
return t;
}
void thread_init(struct thread *t, unsigned int flags,
void *(*run)(void *), void *arg) {
sched_priority_t priority;
assert(t);
assert(run);
assert(thread_stack_get(t));
assert(thread_stack_get_size(t));
t->id = id_counter++; /* setup thread ID */
dlist_init(&t->thread_link); /* default unlink value */
t->critical_count = __CRITICAL_COUNT(CRITICAL_SCHED_LOCK);
t->siglock = 0;
t->lock = SPIN_UNLOCKED;
t->ready = false;
t->active = false;
t->waiting = true;
t->state = TS_INIT;
/* set executive function and arguments pointer */
t->run = run;
t->run_arg = arg;
t->joining = NULL;
//...
/* cpu context init */
context_init(&t->context, true); /* setup default value of CPU registers */
context_set_entry(&t->context, thread_trampoline);/*set entry (IP register*/
/* setup stack pointer to the top of allocated memory
* The structure of kernel thread stack follow:
* +++++++++++++++ top
* |
* v
* the thread structure
* xxxxxxx
* the end
* +++++++++++++++ bottom (t->stack - allocated memory for the stack)
*/
context_set_stack(&t->context,
thread_stack_get(t) + thread_stack_get_size(t));
sigstate_init(&t->sigstate);
/* Initializes scheduler strategy data of the thread */
runq_item_init(&t->sched_attr.runq_link);
sched_affinity_init(t);
sched_timing_init(t);
}
Waiting Mode
A thread can give its time to another state by some reasons; for example, having called the sleep function. So the current thread goes from the operating to waiting mode. If in case of cooperative scheduler we just stated an activity flag, in this case we will keep our thread in another queue. In order not to lose the thread, it is usually stored in a special queue. For example, when trying to capture an occupied mutex, before falling asleep the thread places itself into the queue of waiting for mutex threads. And when the event, which the thread is waiting for, happens, it will wake him up and we will be able to return the thread to the queue of finished ones.
Thread Termination
The thread is in waiting state here. If the thread has performed the processing function and has terminated routinely, resources should be deallocated. I have already described this process when talking about exit state redundancy. Let’s consider this function implementation.
void __attribute__((noreturn)) thread_exit(void *ret) {
struct thread *current = thread_self();
struct task *task = task_self();
struct thread *joining;
/* We can not free the main thread */
if (task->main_thread == current) {
/* We are last thread. */
task_exit(ret);
/* NOTREACHED */
}
sched_lock();
current->waiting = true;
current->state |= TS_EXITED;
/* Wake up a joining thread (if any).
* Note that joining and run_ret are both in a union. */
joining = current->joining;
if (joining) {
current->run_ret = ret;
sched_wakeup(joining);
}
if (current->state & TS_DETACHED)
/* No one references this thread anymore. Time to delete it. */
thread_delete(current);
schedule();
/* NOTREACHED */
sched_unlock(); /* just to be honest */
panic("Returning from thread_exit()");
}
Jumping-Off Place for Processing Function Call
We have mentioned more than once that when a thread terminates, it should deallocate resources. I’d rather not call thread_exit function — after a thread has executed its function, we rarely need to terminate it in extraordinary way, not routinely. Besides, we need to prepare an initial context, doing which every time is unnecessary. So the thread will start with a thread_trampoline cover-function. It serves to prepare the initial context and terminate the thread properly.
static void __attribute__((noreturn)) thread_trampoline(void) {
struct thread *current = thread_self();
void *res;
assert(!critical_allows(CRITICAL_SCHED_LOCK), "0x%x", (uint32_t)__critical_count);
sched_ack_switched();
assert(!critical_inside(CRITICAL_SCHED_LOCK));
/* execute user function handler */
res = current->run(current->run_arg);
thread_exit(res);
/* NOTREACHED */
}
Summary: Thread Structure Description
 In order to describe the task in case of preemptive scheduler we will need quite a complex structure. It contains:
In order to describe the task in case of preemptive scheduler we will need quite a complex structure. It contains:
- information about processor registers (context).
- Information about the task state, whether it’s ready to be performed or waiting for some resource deallocation.
- identifier. In case with an array it’s an index in it. But if threads can be added and deleted, you’d better use a queue, where identifiers will be useful.
- start function and its arguments, possibly even a return result.
- address of a piece of memory, which is allocated for the stack as it needs to be deallocated when exiting the thread.
So, the structure description in our project is the following:
struct thread {
unsigned int critical_count;
unsigned int siglock;
spinlock_t lock; /**< Protects wait state and others. */
unsigned int active; /**< Running on a CPU. TODO SMP-only. */
unsigned int ready; /**< Managed by the scheduler. */
unsigned int waiting; /**< Waiting for an event. */
unsigned int state; /**< Thread-specific state. */
struct context context; /**< Architecture-dependent CPU state. */
void *(*run)(void *); /**< Start routine. */
void *run_arg; /**< Argument to pass to start routine. */
union {
void *run_ret; /**< Return value of the routine. */
void *joining; /**< A joining thread (if any). */
} /* unnamed */;
thread_stack_t stack; /**< Handler for work with thread stack */
__thread_id_t id; /**< Unique identifier. */
struct task *task; /**< Task belong to. */
struct dlist_head thread_link; /**< list's link holding task threads. */
struct sigstate sigstate; /**< Pending signal(s). */
struct sched_attr sched_attr; /**< Scheduler-private data. */
thread_local_t local;
thread_cancel_t cleanups;
};
There are some fields in the structure that haven’t been described in the article (sigstate, local, cleanups). They are necessary for support of full POSIX threads (pthread) and aren’t fundamental within this article.
Scheduler and Scheduling Strategy
Reminding you that we have a thread structure, containing context and we can switch this context. Besides, we have a system timer which counts time slices. In other words, we have environment for scheduler operating. The scheduler task is to allocate processor time between threads. The scheduler has a queue of ready threads, which he operates on in order to define the next active thread. The rules, according to which the scheduler chooses the thread, will be called a scheduling strategy. The main function of the scheduling strategy is operating with the queue of ready threads: adding, deleting and deriving the next ready thread. The scheduler acting will depend on the way these functions are carried out. Since we have defined an individual concept, we will separate it into an entity. We have described the interface as follows:
extern void runq_init(runq_t *queue);
extern void runq_insert(runq_t *queue, struct thread *thread);
extern void runq_remove(runq_t *queue, struct thread *thread);
extern struct thread *runq_extract(runq_t *queue);
extern void runq_item_init(runq_item_t *runq_link);
Let’s consider implementation of a scheduling strategy in details.
Example of Scheduling Strategy
I will consider the most primitive scheduling strategy as an example, so that we would concentrate on peculiarities of the preemptive scheduler. The threads in this strategy will be processed in turn without taking priority into account. A new thread and the one having just used its slice are located at the end. The thread which will get processor resources will be taken from the top. The queue will represent a double-linked list. When we add an element, we place it at the end, and when we extract it – we take and delete it from the top.
void runq_item_init(runq_item_t *runq_link) {
dlist_head_init(runq_link);
}
void runq_init(runq_t *queue) {
dlist_init(queue);
}
void runq_insert(runq_t *queue, struct thread *thread) {
dlist_add_prev(&thread->sched_attr.runq_link, queue);
}
void runq_remove(runq_t *queue, struct thread *thread) {
dlist_del(&thread->sched_attr.runq_link);
}
struct thread *runq_extract(runq_t *queue) {
struct thread *thread;
thread = dlist_entry(queue->next, struct thread, sched_attr.runq_link);
runq_remove(queue, thread);
return thread;
}
Scheduler
And now we will move on to the most interesting part – the scheduler description.
Scheduler Startup
The first stage of scheduler operating is its initialization. We need to provide a proper environment for the scheduler. We should prepare a queue of ready threads, add idle thread to this queue and start the timer, according to which time slices will be counted for threads performance.
Scheduler startup code:
int sched_init(struct thread *idle, struct thread *current) {
runq_init(&rq.queue);
rq.lock = SPIN_UNLOCKED;
sched_wakeup(idle);
sched_ticker_init();
return 0;
}
Thread Awakening and Startup
As we learnt from the description of state machine, awakening and startup is one and the same process. This function call is in the scheduler startup; we start idle thread there. So what is happening during awakening? First of all, the mark of waiting is taken away, meaning that the thread isn’t in the waiting state anymore. Then two variants are possible: it either has fallen asleep or not. I will describe why it happens in the next part “Waiting”. If it hasn’t, the thread is still in ready state and awakening is completed in this case. Otherwise we place the thread into the scheduler queue, take away the mark of waiting state and place the ready one. Replanning is called, if priority of the awakened thread if more that of the current one. Pay attention to different blockings: all actions are performed by the disabled breakings. In order to find out how thread awakening and startup is carried out in case of SMP, refer to the project code.
/** Locks: IPL, thread. */
static int __sched_wakeup_ready(struct thread *t) {
int ready;
spin_protected_if (&rq.lock, (ready = t->ready))
t->waiting = false;
return ready;
}
/** Locks: IPL, thread. */
static void __sched_wakeup_waiting(struct thread *t) {
assert(t && t->waiting);
spin_lock(&rq.lock);
__sched_enqueue_set_ready(t);
__sched_wokenup_clear_waiting(t);
spin_unlock(&rq.lock);
}
static inline void __sched_wakeup_smp_inactive(struct thread *t) {
__sched_wakeup_waiting(t);
}
/** Called with IRQs off and thread lock held. */
int __sched_wakeup(struct thread *t) {
int was_waiting = (t->waiting && t->waiting != TW_SMP_WAKING);
if (was_waiting)
if (!__sched_wakeup_ready(t))
__sched_wakeup_smp_inactive(t);
return was_waiting;
}
int sched_wakeup(struct thread *t) {
assert(t);
return SPIN_IPL_PROTECTED_DO(&t->lock, __sched_wakeup(t));
}
Waiting
Change to waiting mode and then proper awakening (when the expected event finally happens) are probably the most difficult tasks in preemptive scheduling. Let’s consider the situation in details. First of all, we should explain the scheduler that we want to waif or some event. The event takes place asynchronously of course, while need to get it synchronously. So we should indicate how the scheduler should choose which event take place. We don’t know when it’s going to happen. For example, we have told the scheduler that we are waiting for events, verified that its occurrence conditions haven’t been executed yet. At this moment a hardware interrupt takes place and it delivers our event. But as we have already performed the check, this information will be lost. We have solved this problem in our project the following way.
Waiting Macro Code
#define SCHED_WAIT_TIMEOUT(cond_expr, timeout) \
((cond_expr) ? 0 : ({ \
int __wait_ret = 0; \
clock_t __wait_timeout = timeout == SCHED_TIMEOUT_INFINITE ? \
SCHED_TIMEOUT_INFINITE : ms2jiffies(timeout); \
\
threadsig_lock(); \
do { \
sched_wait_prepare(); \
\
if (cond_expr) \
break; \
\
__wait_ret = sched_wait_timeout(__wait_timeout, \
&__wait_timeout); \
} while (!__wait_ret); \
\
sched_wait_cleanup(); \
\
threadsig_unlock(); \
__wait_ret; \
}))
The thread can be in superposition of states. When it falls asleep, it’s still active and just sets out an additional waiting flag. During awakening this flag is taken away and only if the thread has reached the scheduler and left the active threads queue, it will be added there again. If we consider the described things at the picture, it will look like the following:
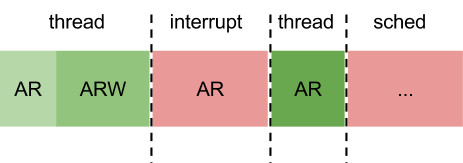
A — active R — ready W — wait
States are denoted by letters. Light green color – thread state till wait_prepare, green — after wait_prepare, dark green – replanning call by the thread. If the event doesn’t happen before replanning, the thread will fall asleep and wait for awakening:

Replanning
The main task for the scheduler is replanning. So let’s consider how it’s implemented in our project. First of all, replanning should be performed when the scheduler is blocked. Secondly, we want to give a capacity of allowing thread preempting or not. So we have extracted the logical operation to a separate function, surrounded its call by blockings and called it, having indicated that we don’t allow preempting in this place. Then actions with ready threads queue take place. If the active thread at the moment of replanning isn’t going to fall asleep (if it doesn’t have a waiting state set out) we just add it to the scheduler thread queue. Then we will take the most priority thread from the queue. The rules of this thread are implemented with the help of the scheduling strategy. If the active thread concurs with the one we have taken out of the queue, we don’t need replanning and can just exit and continue the thread execution. If replanning is required, context_switch and sched_switch function are called. In this function are performed actions which the scheduler needs. If the thread is going to fall asleep and is in waiting mode, it will not get into the scheduler queue and mark tag is taken off. Finally, signals processing takes place, but, as I have mentioned before, it’s beyond this article.
static void sched_switch(struct thread *prev, struct thread *next) {
sched_prepare_switch(prev, next);
trace_point(__func__);
/* Preserve initial semantics of prev/next. */
cpudata_var(saved_prev) = prev;
thread_set_current(next);
context_switch(&prev->context, &next->context); /* implies cc barrier */
prev = cpudata_var(saved_prev);
sched_finish_switch(prev);
}
static void __schedule(int preempt) {
struct thread *prev, *next;
ipl_t ipl;
prev = thread_self();
assert(!sched_in_interrupt());
ipl = spin_lock_ipl(&rq.lock);
if (!preempt && prev->waiting)
prev->ready = false;
else
__sched_enqueue(prev);
next = runq_extract(&rq.queue);
spin_unlock(&rq.lock);
if (prev != next)
sched_switch(prev, next);
ipl_restore(ipl);
assert(thread_self() == prev);
if (!prev->siglock) {
thread_signal_handle();
}
}
void schedule(void) {
sched_lock();
__schedule(0);
sched_unlock();
}
Check of Multithreading Operation
I used the following code as an example:
#include
#include
#include
#include
#include
#include
/**
* This macro is used to register this example at the system.
*/
EMBOX_EXAMPLE(run);
/* configs */
#define CONF_THREADS_QUANTITY 0x8 /* number of executing threads */
#define CONF_HANDLER_REPEAT_NUMBER 300 /* number of circle loop repeats*/
/** The thread handler function. It's used for each started thread */
static void *thread_handler(void *args) {
int i;
/* print a thread structure address and a thread's ID */
for(i = 0; i < CONF_HANDLER_REPEAT_NUMBER; i ++) {
printf("%d", *(int *)args);
}
return thread_self();
}
/**
* Example's executing routine
* It has been declared by the macro EMBOX_EXAMPLE
*/
static int run(int argc, char **argv) {
struct thread *thr[CONF_THREADS_QUANTITY];
int data[CONF_THREADS_QUANTITY];
void *ret;
int i;
/* starting all threads */
for(i = 0; i < ARRAY_SIZE(thr); i ++) {
data[i] = i;
thr[i] = thread_create(0, thread_handler, &data[i]);
}
/* waiting until all threads finish and print return value*/
for(i = 0; i < ARRAY_SIZE(thr); i ++) {
thread_join(thr[i], &ret);
}
printf("\n");
return ENOERR;
}
It’s almost a common application. EMBOX_EXAMPLE(run) macro defines the entry point into the specific type of our modules. thread_join function waits for thread termination, I haven’t considered it either. It’s already enough for one article. Startup result of this example on qemu within the limits of our project is the following: 
As you can see by results, at first threads are executed one by one and then the scheduler gives them time by turns. There is some disagreement at the end. I think it’s a consequence of the fact that the scheduler has quite a rough accuracy (incomparable with one digit lead to display). That’s why during first passes threads can perform different quantity of cycles. Anyway, if you are interested, download the project and try all the abovementioned in practice. If this topic sounds interesting, I could continue telling about scheduling as a lot of topics still need to be covered.
Ropes — Fast Strings

Comments