There are plenty of articles on this subject, but they do not review real-life problems. I am going to try to fix this. We use Bayes’ Theorem (a.k.a. Bayes’ law or Bayes’ rule) to filter spam in recommendation services and for ratings system. A great number of algorithms of fuzzy searches would be impossible without it. Besides, the theorem is the cause of holy wars between mathematicians.
Introduction
Let’s start from the very beginning. If one event occurrence either increases, or decreases the probability of other event occurrence, such events are called dependent. Probability theory does not study cause-and-effect relations. Therefore, dependent events are not necessarily effects of each other, the relation is not always obvious. For example, “a person has blue eyes” and “a person knows Arabic” are dependent events, as Arabian people rarely have blue eyes.
Let’s introduce the following notions:
-
P(A) is the probability of A event occurrence.
-
P(AB) is the probability of both events occurrence. It does not matter, in which order the events occur: P(AB)=P(BA).
-
P(A|B) is the probability of A event occurrence, provided that B event has already occurred.
Let’s think. What is the probability of occurrence of two events at the same time? P(AB). It is equal to the probability of the first event occurrence multiplied by the probability of the second event, in case if the first event occurs. P(AB)=P(A)P(B|A). Now, let’s remember that P(AB)= P(BA). We will get P(A)P(B|A)=P(B)P(A|B). Let’s shift P(B) to the left. We will get Bayes’ equation:

It’s so simple that 300 years ago a priest derived it. But this fact does not diminish the theorem practical value. It allows to solve an “inverse problem” and estimate the situation according to test results.
Direct and Inverse Problems
We can describe a direct problem the following way: find the probability of one of effects by a reason. For example, there’s an absolutely symmetric coin (the probability of getting heads, as well as tails, as the face-up side, is 1/2). We should calculate the probability of getting heads twice when tossing a coin. It is obvious that it equals to 1/2 * 1/2 =1/4.
But the problem is that we do not know the probability of some event in minority of cases only. Almost all of them are artificial. For example, gambling games. At the same time, there’s nothing absolute in nature. ½ probability of getting heads when tossing a real coin is only approximate. We can say that the direct task studies some spherical cows.
In practice, the inverse task is more important. It is to estimate a situation according to test results. But the problem of the task is that its solution is more complex. Mainly due to the fact that our solution will not be P=С point, but some P=f(x) function.
For example, there is a coin and we are to estimate the probability of getting tails with the help of tests. If we have tossed a coin once and got heads, this does not mean that we will always get them. If we have tossed a coin and got heads twice, this does not mean that this will always be the case. To get the probability of getting tails, we should toss a coin infinite number of times. It’s impossible in practice. We always calculate the probability of some event with some accuracy.
We have to use some function. It is commonly stated as P(p=x|s tails, f heads) and named as probability density function. We should read it as follows: the probability of getting heads is equal to x, provided that there have been s tails and f heads according to test results. It is easier to consider p as some feature, not probability of the coin. Then we will read it like this: the probability of p=x…
Looking ahead, we can say that after flipping a coin 1000 times and getting 500 heads and then flipping another coin 10000 times and getting 5000 heads, the probability density will look like the following:

Since it is not a point, but a curve, we should use confidence intervals. For instance, if they say that 80% confidence interval for p is equal to 45% to 55%, this means that p is located between 45% and 55% with a probability of 80%.
Binomial Distribution
For simplicity, we are going to review binomial distribution. It’s the distribution of a number of “successes” in the sequence of some number of independent random experiments. The probability of “success” in them is constant. We can observe this distribution almost always when there is a sequence of tests with two possible results. For example, when tossing a coin several times, or estimating CTR or users conversion rate.
As an example, we are going to assume that we should estimate the probability of getting tails when tossing a coin. We have tossed it several times and got f heads and s tails. Let’s mark this event as [s,f] and use it in Bayes’ Theorem instead of B. When p is equal to some number, we will indicate the event as p=x and replace A with it.
P([s,d]|p=x). The probability of getting [s,d], when p=x, provided that p=x, we know that P([s,f]|p=x)=K(f,s) * xs (1-x)f. In which K(f,s) is the binomial coefficient. Thus, we will get the following:

P([s,f]) is unknown. Since there are factorials in the binomial coefficient, it is quite problematic to calculate it. But we can solve these problems. The total probability of all possible x should be equal to 1.
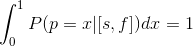
With the help of simple conversions we are going to get the following equation:
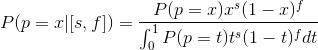
It’s quite easy to code it in 10 lines only:
// f(x) some P(p=x) function
m = 10000; // the number of points
eq = new Array(); // P(p=x|[s,f])
sum = 0;
for(i=0; iHowever, P(p=x) is still unknown. It expresses degree of the probability that p=x, provided that we have no data about the experiment. This function is called a priori. The holy war in Probability Theory took place because of it. We cannot calculate the a priori in a pure mathematical way. We can only define it subjectively and cannot solve the inverse task without it.
Holy War
The classic interpretation followers (the Frequency approach) think that all possible p are equally probable before the experiment beginning. Thus, we should “forget” the data we know before it. As for their opponents, the followers of the Bayesian approach, they think that we should define some a priori on the basis of our knowledge before the experiment begins. This divergence is fundamental. Besides, the definition of probability differs in these groups.
By the way, the Theorem creator, Thomas Bayes, had died 200 years before the Holy War began. Thus, he is not close related to this dispute. Bayes’ Theorem is a part of both competing theories.
Frequentist approach is more suitable for science, where it is necessary to objectively prove some hypothesis. For example, prove that mortality from a medicine is less than some threshold. But if you have to arrive at a decision considering all the available information, you’d better use the Bayesian approach.
Frequentist approach is not suitable for predicting. By the way, confidence interval equations calculate a confidence interval according to the frequentists. As a rule, the Bayesian approach followers use Beta distribution for the binomial one. When a=1 and b=1, it degenerates into continuous distribution used by their opponents. As a result, the equation looks like this:
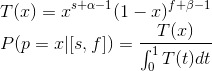
It is a universal formula. When using the Frequency approach, we should define that b=a=1. The Bayesian approach followers should choose these parameters somehow and obtain a plausible beta distribution. Knowing a and b, we can use equations of the frequency approach. For example, in order to calculate the confidence interval. Suppose we have chosen a=4.5, b=20. There are 50 successes and 100 fails. In order to calculate the confidence interval in the Bayesian approach, we should introduce 53.5 (50+4.5-1) and 119 fails into a regular equation.
However, we have no criteria for selecting a and b. In the next part I am going to tell you about the way we can choose them by statistical data.
Prediction
It is quite logical to use mathematical expectation as a prediction. We can obtain its equation from the formula of mathematical expectation for the beta distribution. We will get the following:
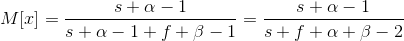
For example, there is a website with articles. There is a like button under each of them. If we sort by the number of likes, new articles will hardly beat the old ones. But if we sort by a ratio of likes to shows, the articles with one like will beat the article with 1000 shows and 999 likes. Thus, it is more reasonable to sort by the last equation, but we should somehow define a and b anyway. The easiest way to do this is to use 2 basic things of the beta distribution. They are mathematical expectation (the average number) and dispersion (departure from the average).
Let L be the average probability of a like. According to mathematical expectation of the beta distribution, L=a/(a+b) =>a+b=a/L=> aL+bL=a => b=a(1/L — 1). Let’s substitute it into the equation of dispersion:
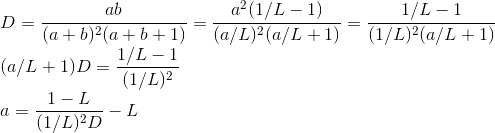
In pseudo code, it is going to look like one below:
L = 0;
L2 = 0; //The number of squares
foreach(articles as article){
p = article.likes/article.shows;
L += p;
L2 += p^2;
}
n = count(articles);
D = (L2 - L^2/n) / (n-1); // Dispersion
L = L/n; // average
a = L^2*(1-L) / D-L;
b = a*(1/L — 1);
foreach(articles as article)
article.forecast = (article.likes+a-1) / (article.shows+a+b-2)Despite the fact that the given choice of a and b seems to be objective, it’s not strict mathematics. First of all, it is far from certain that articles likeability is affected by the Beta distribution. In contrast to binomial distribution, this one is “not physical”, it has been introduced for convenience. Actually, we have adjusted the curve to statistical data. Besides, there can be several adjustment variants.
A Chance to Beat All
Suppose we have run an А/B test of several variants of a website design. After getting some results, we’re thinking, whether we should stop it. Stopping too early, we can choose a wrong variant. But we should stop anyway. We can estimate confidence intervals, but their analysis is complicated. At least due to the fact that depending on the value coefficient, we can obtain different confidence intervals. Now, I will show you how to calculate the probability of one variant being better than all the other ones.
Besides dependent events, there are also independent ones. For such events, P(A|B)=P(A). Thus, P(AB)=P(B)P(A|B)=P(A)P(B). To begin with, we should show that the variants are independent. By the way, it is valid to compare confidence intervals, but only if the variants are independent. As we have already said, the Frequency approach followers reject all the data, except for the experiment itself. Variants are single experiments. Therefore, each of them depends on its results only. Thus, they are independent.
As for the Bayesian approach, the proof is more complicated. Mainly, due to the fact that a priori “isolates” variants one from another. For example, such events as blue eyes and knows Arabic are dependent. As for “An Arabian knows Arabic” and “An Arabian has blue eyes”, they are independent, as interdependence between the first two events is deflated by “the person is Arabian”. In our case, it’s better to write P(p=x) the following way: P(p=x|apriori=f(x)). Everything depends on the a priori function choice. As for P(pi=x|apriori=f(x)) and P(pj=x|apriori=f(x)) events, they are independent, as the only interconnection between them is the a priori function.
Let’s introduce P(p
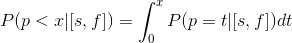
We have just “put together” all point probabilities.
Let’s abstract a bit. I’m going to provide an equation of total probability. Suppose there are three events: A, B, W. The first two are mutually exclusive. Besides, one of them should occur. Thus, just one event can occur of these two. Only one of the events will take place, but not both of them. For example, a person’s gender or getting heads/tails in one throw. W event can occur in two cases only: together with A and together with B.
P(W)=P(AW)+P(BW)=P(A)*P(W|A)+P(B)*P(W|B). It’s pretty much the same when there are more events. Even when there is an infinite number of events. Therefore, we can make the following conversions:
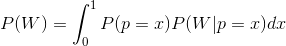
Suppose there are n variants. We know the number of successes and fails for each of them. [s_1,f_1], ..., [s_n,f_n]. For simplicity, we will omit data from the equation. Thus, instead of P(W|[s_1,f_1], ..., [s_n,f_n]), we will just write P(W). Let’s denote the probability of i variant being better than all other ones (Chance To Beat All) and shorten the equation a bit:
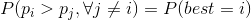
∀j≠i is for all j that are not equal to i. Put simply, all of this means the probability of pi being greater than all others.
Let’s apply the total probability equation:
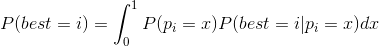
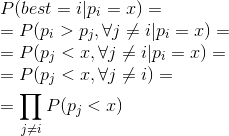
The first conversion just changes the form of equation a bit. Since there is a conditional probability, the second conversion replaces pi with x. Whereas p_i does not depend on p_j, we can perform the third conversion. As a result, it’s equal to the probability of all p_j, except for i, being less than x. Since the variants are independent, P(AB)=P(A)*P(B), meaning that we convert all of this into the product probability.
As a result, the equation will look like this:
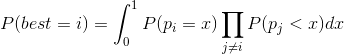
We can calculate all of this in linear time:
m=10000;//the number of points
foreach(variants as cur){
cur.eq=Array();//P(p=x)
cur.less=Array();//P(pWhen there are two variants only (Chance to beat baseline/origin, CTBO), we can calculate this chance in constant time with the help of normal approximation. In the general case, we cannot solve it in constant time. At least, Google did not manage to do it. There were CTBA and CTBO in Google WebSite Optimizer. After the shift to Analytics, there remained a less handy CTBO. The only explanation is the fact that CTBA consumes too many resources on the CTBA calculation.
By the way, there are two things to help you understand, where you have properly organized the algorithm. The summarized CTBA should be equal to 1. You can also compare your result with Google WebSite Optimizer screenshots. Here are some comparisons of our free HTraffic Calc statistical calculator to Google WebSite Optimizer.
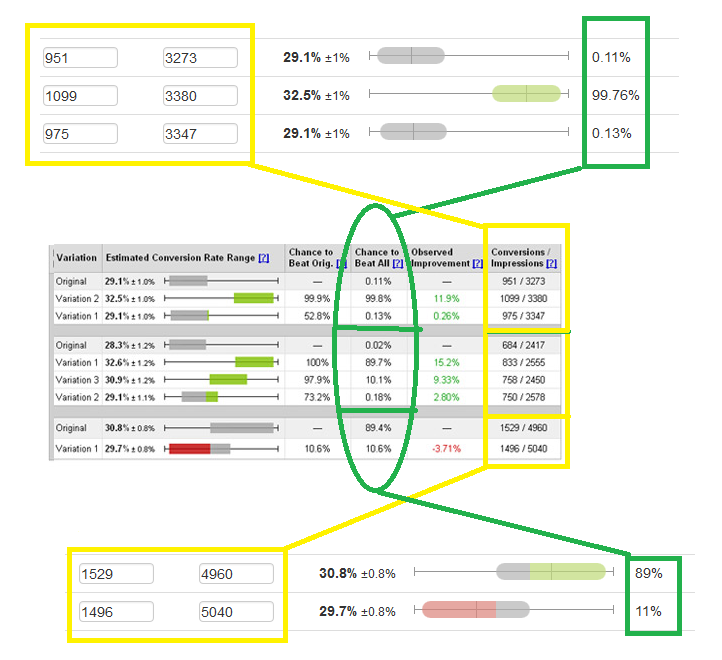
The difference in the last equation is caused by the fact of using “smart adjustment”. All the data is equal without the adjustment.
CTBA Peculiarities
Suppose the probability of success is far from 0.5. The number of tests (coins tossing or banner shows) is small in some variants. Besides, if the number of tests differs a lot in several variants, you should either define an a priori, or adjust the number of tests. This concerns not only CTBA, but also confidence intervals comparison.
As you can see from the screenshot, the second variant has all chances to beat the first one. This happens due to the fact that we have chosen even distribution as an a priori. Its mathematic expectation is equal to 0.5, which is greater than 0.3. Therefore, the variant with a less number of tests will get a bonus. From the Frequency approach point of view, the experiment is violated. All the variants should have the equal number of tests. Thus, you should adjust the number of tests by rejecting some tests of one of the variants. You can also use the Bayesian approach and choose an a priori.
2 comments
Opps.
Upload image