Having read some articles about tries (aka prefix trees aka radix trees), I decided to write one of my own. Today we are going to talk about a trie implementation in C++. We will also compare a string search with AVL and Radix tree.
Intro

A trie is an ordered tree data structure that is used to store a dynamic set or associative array where the keys are usually strings. We are going to take a look at the implementation of prefix trees for storing ASCII strings. Each string ends with a terminal symbol that will never repeat in a string again. To indicate terminal symbols in pictures and examples, we will use the dollar sign. To indicate them in the code, we’re going to use the null symbol. Thus, in our implementation the strings will be standard C ones, which allows to use the standard string.h library. All the mentioned above should be easily carried over to other alphabets.
In a regular radix tree each edge is assigned with some symbol. As for root nodes, they store some service(user) information. Thus, any route from a tree root to one of its leaves defines precisely only one string. This string is considered to be stored in the specified tree. For instance, a trie stores the following set of strings: {abab$, aba$, bc$, b$, bac$, baca$} (see the picture below). The root is on the left, leaves (their number coincides with the number of strings) are on the right. The root of baca$ string is highlighted in red.

A cautious reader will notice that this way a trie represents a regular deterministic finite-state machine, the states of which corresponds to leaves of a trie. Trie implementation in libdatrie library is based exactly on this concept. The automaton is represented with the help of arrays.
To make an automaton smaller, represent a trie in a partially compressed form. Such form means that all “tails” of the tree (areas with no branches) are packed in strings (see the picture A below). We can also compress in a similar way all the chains with no branches (picture B). In this case the tree will no longer be a finite-state automaton, or rather it will still be an automaton, but for an alphabet of strings, not symbols. Working with a tree like with an automaton relies on the fact that the alphabet size is finite and we can define its serial number by any symbol in the alphabet in O(1) of time (the same will not work for strings). Thus, its implementation with the help of arrays becomes problematic. But when implementing with the help of pointers, there should be no problems with strings storage.

Representing a Trie Using Pointers
Let’s see how we can use pointers to represent trie edges. First of all, we should realize that in this case, it will be really uncomfortable to store information in trie edges. Therefore, we should relocate symbol chains from edges to root nodes. Use an obvious feature of oriented trees: just one edge enters any node, except for the root one.
We are going to get the following structure:

There’s another problem, as an outdegree of a tree node can be random (even of the current alphabet size). To solve this problem, let’s apply a standard method: store a list of children nodes in each node. The list will be singly linked, so we will store only a head (older sister) in a node. This will allow us to reject an empty root. Now, a trie will be represented with a pointer to the list head of children nodes of the old root (i.e. we replace a tree with a forest). Thus, each node will store precisely two pointers: link – to the oldest node, next –to its younger sister. The following picture shows the process of such transformation; blue arrows correspond to link pointers, red arrows – to next pointers.

In order to understand the principle of working with a tree, you should keep in mind the scheme that is presented in the picture on the left. Meanwhile, the actual representation of a tree will be like in the picture on the right.
So, we have moved on from the tree with a variable outdegree (a regular tree) to the binary tree, in which link and next are pointers to the right and left subtrees, like in the picture below:

Now we can get down to implementation. A tree node is a chain of key symbols, its len length and link and next pointers. The chain is not required to end with a terminal symbol, so we should know its length. There’s also a minimal constructor that creates a trivial tree consisting of one node with a given key (to copy symbols, use a standard strncpy function) and an even more minimal destructor.
struct node // a structure to represent tree nodes
{
char* key;
int len;
node* link;
node* next;
node(char* x, int n) : len(n), link(0), next(0)
{
key = new char[n];
strncpy(key,x,n);
}
~node() { delete[] key; }
};Searching for Keys
The first operation we will take a look at is inserting a new string in a prefix tree. The search idea is standard. We will move from the tree root. If the root is empty, the search is unsuccessful. If otherwise, we will compare the key in the node with a current x string. Use the following function that will calculate the length of the biggest common prefix of two strings of the given length.
int prefix(char* x, int n, char* key, int m) // length of the biggest common prefix of x and key strings
{
for( int k=0; kWhen searching, we are interested in the following cases:
- A common prefix can be empty. In this case we will continue to search recursively at the child node of the given one. i.e. we will pass by next reference;
- If a common prefix is equal to the sought x string, the search is successful, we’ve found the node. That’s when we use the fact that we can find the end of a string, which has a terminal symbol, in the tree leaf only.
- A common prefix is congruent with the key, but is not congruent with x. In this case we will recursively go to the parent child node by using a link reference and passing it x string without the found prefix.
If we have found the common prefix, but it is not congruent with the key, the search is unsuccessful as well.
node* find(node* t, char* x, int n=0) // x key search in t tree
{
if( !n ) n = strlen(x)+1;
if( !t ) return 0;
int k = prefix(x,n,t->key,t->len);
if( k==0 ) return find(t->next,x,n); // let’s look for the child’s node
if( k==n ) return t;
if( k==t->len ) return find(t->link,x+k,n-k); // let’s look for at the child’s node
return 0;
}By default, n length of x string is zero so that we could call the search function by specifying a tree root and a search string.
...
node* p = find(t,"baca");
...The following picture shows the process of searching three strings (one of them is successful, the other ones – not so much) in the provided above tree.

We should note that in case of success, the search function returns a pointer to the tree leaf, where the search was finished. This node should contain all the information connected with the sought string.
Inserting Keys
A new key insertion (as well as in binary search tress) is similar to key search. Of course, there are some differences. First of all, in case of an empty tree, we should create a node (a trivial tree) with the defined key and return a pointer to this node. Secondly, if the length of a common prefix of the current key and the current x string is more than zero, but less than the key length (the second case of an unsuccessful search), we should split the current node into two, leave the found prefix in the parent node and place the remaining part of the key into p child node. To perform this operation, use split function. After splitting the node, go on inserting x string in a p node without a found prefix.

The node splitting code:
void split(node* t, int k) // dividing t node according to k key symbol
{
node* p = new node(t->key+k,t->len-k);
p->link = t->link;
t->link = p;
char* a = new char[k];
strncpy(a,t->key,k);
delete[] t->key;
t->key = a;
t->len = k;
}Insertion code:
node* insert(node* t, char* x, int n=0) // inserting x key in t tree
{
if( !n ) n = strlen(x)+1;
if( !t ) return new node(x,n);
int k = prefix(x,n,t->key,t->len);
if( k==0 ) t->next = insert(t->next,x,n);
else if( klen ) // cut or not to cut?
split(t,k);
t->link = insert(t->link,x+k,n-k);
}
return t;
} The following picture represents abaca$ and abcd$ keys insertion in the mentioned above tree:

You should note, that if the given x string is already in the tree, there will be made no insertion. In this case a prefix tree behaves as a proper set.
Deleting Keys
As always, key deletion is the most difficult operation. Though in case of tries, it is not that scary. The thing is that when we delete a key, we delete just one leaf node corresponding to some suffix of the key. At first, we should find this node. If the search is successful, we delete it ands return the pointer to the younger sister of the given node (since it is a leaf, it has no children, but can have sisters).

At that, we could finish the deleting process, but there’s one problem. After the node deletion, there can form a chain of t and p nodes, in which t node has just one p child node. Therefore, if we want to keep the tree compressed, we should join these two nodes into one by performing merge operation.
The code of merge operation is quite trite. We create a new key, then move the subtree of a p node to t and delete p node.
void join(node* t) // t and t->link nodes merge
{
node* p = t->link;
char* a = new char[t->len+p->len];
strncpy(a,t->key,t->len);
strncpy(a+t->len,p->key,p->len);
delete[] t->key;
t->key = a;
t->len += p->len;
t->link = p->link;
delete p;
}The older node is in charge of merging as the younger one does not have the information about its parent. Merge execution has the following criteria:
- Key deletion by link reference, not next;
- After deletion, a new link reference does not have next reference. There’s just one child node, so we can merge it with the current one.
node* remove(node* t, char* x, int n=0) // deleting x key from t tree
{
if( !n ) n = strlen(x)+1;
if( !t ) return 0;
int k = prefix(x,n,t->key,t->len);
if( k==n ) // deleting a leaf
{
znode* p = t->next;
delete t;
return p;
}
if( k==0 ) t->next = remove(t->next, x, n);
else if( k==t->len )
{
t->link = remove(t->link, x+k, n-k);
if( t->link && !t->link->next ) // does t node have just one sister node?
join(t);
}
return t;
}Examples of deleting keys without merging:

with merging:

Efficiency
There have been carried out a computational investigation on comparing AVL and prefix trees as for operation time and memory consumption. As for me, the result was a bit bewildering. Anyway, let’s go step by step. There have been formed 8 test string sets. The following table represents their features:
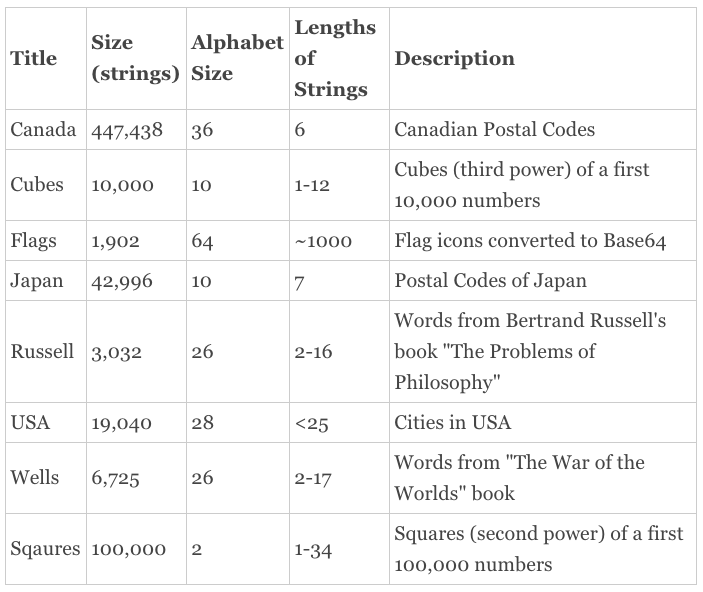
First of all, they measured the build time of a tree according to the given set of strings and time for searching in it all the keys of the same set (i.e. successful search only). The below graph presents the comparison of AVL tree and a prefix tree (radix tree) build time. You can see that a prefix tree builds up a bit faster.

The following chart compares the time spent on searching all keys for the same two trees. A balanced binary tree spends two times less time on searching, than a prefix one.

Finally, let’s take a look at memory requirements for one symbol. The results are presented in the following graph:

On average, there are about 2 bytes per one symbol, which is not bad. But in case of flags a prefix tree spends less than 1 byte on 1 symbol (there are plenty of common long prefixes).
Thus, there have been found no winner. It’s worth to compare the operation time of these two trees as for the number of strings. But according to the provided above charts, there would be nothing revolutionary. Of course, it would also be interesting to compare these two approaches with hash tables…
Thanks for your attention!
You’re most welcome to share your thoughts and comments.
P.S. Does anyone know where to get a large datasets open to the public?
0 comments
Upload image