
The number of methods to rack your brains with the help of C++ is increasing with every new release.
Especially when the approach to playing field implementation isn’t changed and all the computations are carried out on types rather than constants.
But would it be that difficult to write a multipurpose computer on types, which would be handier for programming rather than a cellular automaton? As it turned out, it’s not difficult. I spent 30 times more hours to write this article than to write and debug the code itself.
I wanted it to be written approx the following way:
#include
#include
#include
int main()
{
// Natural numbers representation in the form of lambda-abstractions
typedef ChurchEncode<2> Two; // 2 = λfx.f (f x)
typedef ChurchEncode<3> Three; // 3 = λfx.f (f (f x))
// * = λab.λf.a (b f)
typedef Lambda<'a', Lambda<'b', Lambda<'f',
Apply, Apply, Var<'f'> > >
> > > Multiply;
// Calculation (* 2 3)
typedef Eval, Three>> Output;
// Change-over from lambda-abstractions to natural numbers
typedef ChurchDecode And then get following at the output:
ilammy@ferocity ~ $ gcc cpp.cpp
ilammy@ferocity ~ $ ./a.out
6The article turned out too long as I had wanted to tell about all the interesting things that had been used here. It also requires the basic set of knowledge about lambda calculus.
Under the cut you will find another constructive proof of C++ templates Turing-completeness in the form of compile-time interpreter of no-type lambda calculus (plus dessert in the form of macros and recursion).
(Whereas C++03 compilers require
Syntax
Let’s go. As you know, there are three types for the terms in lambda calculus:
 |
reference variable | v — variable name |
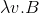 |
abstraction | v — variable name, B — term |
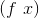 |
application | f and x — terms |
All these constructions should be represented with the help of C++ templates. Types are the values in the template language. Each of the types should contain information about its components. We introduce “there are the following clauses” axiom by declaring them:
template struct Ref; // references
template struct Lam; // abstractions
template struct App; // applciations Though variables in lambda calculus are not full-values.
v variable makes no sense as it is, without an abstraction that links it with some other value. So the term is the reference, not the variable itself. Thus the specification can be a bit simplified:
template struct Ref;
template struct Lam;
template struct App; We used template feature with the help of integer values. char type variables can also be written as strings. It’s very handy as you don’t have to declare each variable used in the program in advance.
It also shows that variables are not values (i.e. C++ types).
Fun Fact
Variable names can be formed by several symbols: 'foo'. Though the apologists of lambda calculus consider it to be a luxury. Second thing is that the meaning of such symbol literals is left to compiler. In rare cases it can result to names collision.
Now, with the help of templates, we can use any lambda terms!
typedef Lam<'f', App, App, Ref<'x'>>>>,
Lam<'x', App, App, Ref<'x'>>>>>> Y; What’s Next?

Now, if you can use terms, you should also learn how to compute them. But it’s not that easy, so at first we will write everything in any declarative programming language and then fix syntax differences. I will use Scheme just because I like it. Any other functional language can be used here. For example, Haskell. (Prolog is even better).
Let's just use traditional lists to write down the terms:
; Y = λf.(λx.f (x x)) (λx.f (x x))
(define Y '(lambda (f) ((lambda (x) (f (x x)))
(lambda (x) (f (x x))) )))Fixing the syntax of lambda calculus:
; Term is a reference, an abstraction or an application.
(define (term? exp)
(or (ref? exp) (lam? exp) (app? exp)) )
; References are written by symbols.
(define (ref? exp) (symbol? exp))
; Application is a list of three elements. —
(define (lam? exp)
(and (list-of? 3 exp)
; Where the first one is lambda symbol.
(eqv? 'lambda (first exp))
; The second one is the list of one symbol.
(list-of? 1 (second exp))
(symbol? (first (second exp)))
; The third one is a term.
(term? (third exp)) ) )
; Application is the list of two terms.
(define (app? exp)
(and (list-of? 2 exp)
(term? (first exp))
(term? (second exp)) ) )Then we’ll define eval function that will interpret the terms, distinguishing them by syntax.
(define (eval exp)
(cond ((ref? exp) (eval-ref exp))
((lam? exp) (eval-lam (first (second exp)) (third exp)))
((app? exp) (eval-app (first exp) (second exp)))
(else (error "eval: syntax error" exp)) ) )Great. But how should we implement the eval-ref? How will the interpreter know the variable value? There is an environment notion for such things. Environments keep connections between variables and their values. That’s why the eval looks the following way — with an additional argument:
(define (eval exp env)
(cond ((ref? exp) (eval-ref exp env))
((lam? exp) (eval-lam (first (second exp)) (third exp) env))
((app? exp) (eval-app (first exp) (second exp) env))
(else (error "Syntax error" exp)) ) )Now it’s easy to determine the reference variable. We need to find the variable's value in the environment:
(define (eval-ref var env)
(lookup var env) )Abstraction value should be an anonymous function of one argument. When the time comes, this function will be called by application. The goal of abstraction is to determine its exp body in the environment, where the var abstraction variable has the value of transferred argument arg. bind function will take care of such environment creation.
(define (eval-lam var exp env)
(lambda (arg)
(eval exp (bind var arg env)) ) )The values of other variables can vary. But in lambda calculus they should be remained the same as in the place of abstraction determination (i.e. taken from env environment). Due to the feature of initial environment conservation such functions are called closures.
And finally, application is an applying fun abstraction value to the arg argument value.
(define (eval-app fun arg env)
((eval fun env) (eval arg env)) )At first the abstraction and its argument are computed and then the call takes place. Thus eval performs reduction of lambda-terms in the applicative order (with call by value).
We just need to define a few functions to work with environments:
- lookup — to search variable value within the environment;
- bind — to create new environments.
(define (bind var val env) ; Associative lists are used for environments:
(cons (cons var val) env) ) ; (bind 'x 1 '((y . 2))) ===> ((x . 1) (y . 1))
; (lookup 'x '((x . 1) (y . 2))) ===> 1
(define (lookup var env) ; (lookup 'y '((x . 1) (y . 2))) ===> 2
(let ((cell (assq var env))) ; (lookup 'z '((x . 1) (y . 2))) ===> #
(if cell (cdr cell)
(error "lookup: unbound variable" var) ) ) ) Great! We have an interpreter of lambda calculus, which is written in a pure functional style (source code). It does even work:
(eval '((lambda (x) x) B)
(bind 'B 42 '()) ) ; ===> 42What Kind of Brackets? What Has C++ to Do with It?

Looking at the source code of the interpreter on Scheme, you can quite easily guess how to write an interpreter of lambda-terms with C++ templates. Reminding you, that the terms are written by the following templates:
template struct Ref;
template struct Lam;
template struct App; Template Functions (not those)
Interpreter-function is called Eval. As there are no functions in templates, we’ll have to do with templates only:
template struct Eval; The call of such function is template instantiation: Eval
Let’s agree, that Eval defines the value type within itself if its value is defined for the passed arguments:
typename Eval::value Such code allows to get Eval call value with Exp and Env arguments (in the form of value type). If the specific call is erroneous (has no sense), value type won’t be determined and we’ll get an error of compilation time.
Eval and Apply
Now with the help of partial template specialization we can declaratively describe Eval behavior. For example, determination of the reference variable is a variable search in the environment with the help of Lookup function (it returns the value via result):
template
struct Eval, Env>
{
typedef typename Lookup::result value;
}; The result of calculating the abstraction is a closure, represented by Closure template type. The closure stores in itself the function (anonymous) and defining environment for this function:
template
struct Eval, Env>
{
typedef Closure, Env> value;
}; The result of application calculation is applying the calculated closure to the calculated argument (executed by Apply function):
template
struct Eval, Env>
{
typedef typename Apply::value,
typename Eval::value>::result value;
}; Thus, Eval is defined for Ref, Lam, App only (and environments by the second argument). The calls of Eval with other arguments just won’t compile.
Let’s go on. Closures are just interpreter data structures, which store two meanings (the function and the environment of its definition). They are implemented by one template:
template struct Closure; All the essence of lambda calculus is concentrated in the definition of Apply function.
Closures are calculated in the environment of its definition, which Bind extends by the
binding the argument of computed function to its actual value:
template struct Apply;
template
struct Apply, Env>, Arg>
{
typedef typename Eval>::value result;
}; (Note, that Apply can be defined not for applying abstraction only.)
Lookup and Bind
We have to look into environments. To begin with, we need a null environment:
struct NullEnv;Then we should implement the environment mechanism with the help of Bind. This data type defines a new environment, in which Var variable is bound with Val value. Values of other variables are defined by the Env environment:
template struct Bind; We gained an original linked list on templates.
Finally, we need to know how to find the value of the necessary variable in this list. It will be in the first list element with an equal name. The search is executed by Lookup function.
template struct Lookup; There’s nothing in the empty environment. If the sought value is in the current environment, we return it. Otherwise, we recursively browse the remaining environments:
template
struct Lookup;
template
struct Lookup>
{
typedef Val result;
};
template
struct Lookup>
{
typedef typename Lookup::result result;
}; The End
That’s how we completely defined the syntax and semantics of lambda calculus via C++ templates in 50 lines. It proves Turing-completeness of the C++ template opening mechanism (provided that the available memory capacity is unlimited.
The definition of Turing machine can be written in 50 lines as well, but it will still be too verbose due to the complex structure. The definition of mu-recursive functions will definitely be shorter, but not much.
So let’s try to carry out a primitive calculation, using the acquired facilities (complete code):
/* The mentioned above definitions */
#include
int main()
{
// 1 = λfx.f x
typedef Lam<'f', Lam<'x', App, Ref<'x'>>>> One;
// 2 = λfx.f (f x)
typedef Lam<'f', Lam<'x', App, App, Ref<'x'>>>>> Two;
// + = λab.λfx.a f (b f x)
typedef Lam<'a', Lam<'b', Lam<'f', Lam<'x',
App, Ref<'f'>>,
App, Ref<'f'>>, Ref<'x'>>>
>>>> Plus;
// Output := (+ 1 2)
typedef Eval, Two>, NullEnv>::value Output;
// Ur… How to put the results out?
Output::invalid_field;
} ilammy@ferocity ~/dev/tlc $ g++ -std=c++11 lc.cpp
lc.cpp: In function «int main()»:
lc.cpp:79:5: error: incomplete type «Output {aka Closure, Ref<'f'> >, App, Ref<'f'> >, Ref<'x'> > > > >, Bind<'b', Closure, App, Ref<'x'> > > > >, NullEnv>, Bind<'a', Closure, Ref<'x'> > > >, NullEnv>, NullEnv> > >}» ...
Output::invalid_field;
^ This way of programs executing isn’t bad, but I would like it to be handier.
Terms Set Extension

First of all, closures of the template interpreter are its internal data structures. C++ types only correspond to them, but not the values. You should operate on them within the interpreter and never bring them outside the limits of the template mechanism. (That’s why they are left as undefined types.)
Secondly, when the arguments are presented in the form of Church numerals, the result of their summation will also be a Church numeral. It’s a function of two arguments, which N times applies the first argument to the second one. (That’s why we got a closure, as states the gcc output.) But what should we do with this function? Because as an arguments we can only pass the same functions!
Indeed, now the interpreter can only understand pure lambda calculus, which have abstractions, applications and variables (which reference to abstractions or applications). The syntax allows creating lambda-terms of these three components only. Any violation of this rule leads to the compilation error.
In order to understand the computation results, an applied lambda calculus should be used, where the set of terms is extended by the elements of some object set. In our case it will be the set of C++ data types.
Let’s define an appropriate term for them:
template struct Inj; It denotes an injection of T type into the set of lambda calculus terms.
After the syntax extension we should clarify the language semantics. We should define the value of a new syntactic construction with the help of Eval. Whereas T is an arbitrary value, the only thing Eval knows about it is the fact that such value exists. An identity is the only denotation we can give to the function in such conditions:
template
struct Eval, Env>
{
typedef T value;
}; Now we can pass numbers (represented by types) as arguments.
struct Zero
{
static const unsigned int interpretation = 0;
};We should also think out the way to pass the function and we’ll be able to convert Church numerals into regukar int. Because if we apply the increment function to zero by N times, then we’ll get a natural N number.
Let’s suppose that we have managed to do it by passing Succ (successor) and Zero types
to the interpreter. We’ll watch what’s happening during the call of such function.
Eval, Inj>, Env>::value
Apply, Env>, Eval, Env>>::result
Apply::result Bingo! In order to determine Succ behavior we should specialize Apply for it!
(similar transformations are called delta-rules)
For example, that’s how an increment function is defined:
struct Succ;
template
struct Apply
{
typedef struct _ {
static const unsigned int interpretation = N::interpretation + 1;
} result;
}; The returned Apply value should be the type that is declared as result. So the increment result is the data type that is structurally identical to Zero, which was mentioned above. This allows to represent natural numbers as non-template data types, saving a possibility of acquiring a general int with the appropriate value.
And now we can finally output the summation result. (complete code)
/* Definitions, mentioned above*/
#include
int main()
{
// 1 = λfx.f x
typedef Lam<'f', Lam<'x', App, Ref<'x'>>>> One;
// 2 = λfx.f (f x)
typedef Lam<'f', Lam<'x', App, App, Ref<'x'>>>>> Two;
// + = λab.λfx.a f (b f x)
typedef Lam<'a', Lam<'b', Lam<'f', Lam<'x',
App, Ref<'f'>>,
App, Ref<'f'>>, Ref<'x'>>>
>>>> Plus;
// Sum = (+ 1 2)
typedef App, Two> Sum;
// Result := (Sum +1 =0)
typedef App>, Inj> Output;
typedef Eval::value Result;
std::cout << Result::interpretation;
} ilammy@ferocity ~/dev/tlc $ g++ -std=c++11 lc.cpp
ilammy@ferocity ~/dev/tlc $ ./a.out
3Global Environment and Free Variables
I guess you’ve already noticed that we always call Eval with an empty environment in main() and “inlining” all the required abstractions. But it’s not necessary at all. If we send some environment to the first call of Eval, then it will be global for the term being calculated as it defines the values of free variables, which are not bound by lambda-abstractions with anything.But we can’t just place the type-function in the environment. That's because there are values. So at first we should calculate them (github code):
/* ... */
#include
int main()
{
/* One, Two, Plus definitions are missed */
// Unchurch = λn.(n +1 =0), Church numerals conversion to int
typedef Lam<'n', App, Ref<'I'>>, Ref<'O'>>> Unchurch;
// Result := (Unchurch (+ 1 2))
typedef Eval,
App, Ref<'1'>>, Ref<'2'>>>,
Bind<'+', typename Eval::value,
Bind<'1', typename Eval::value,
Bind<'2', typename Eval::value,
Bind<'U', typename Eval>
>::value,
NullEnv>>>>
>::value Result;
std::cout << Result::interpretation;
} Environments represent the interpreter memory. Compiled functions would be located there if it were a compiler with a linker. In case of interpreter they are in “precalculated” state — they have already been run through Eval.
We should also pay attention to Unchurch free variables. They enter the environment without any Inj around as these values are represented exactly this way in the interpreter memory. Inj is required for them to be written in the program text only (in lambda-terms).
Macros

Isn’t anyone sick and tired of the fact that in order to write several arguments functions they should be manually carried? And all of these Ref<'foo'> all the time?
By the way, even in lambda calculus the following shortenings are usual:
| Before | After |
|---|---|
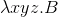 |
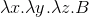 |
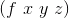 |
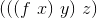 |
There are many approaches to macros implementation. We should choose the simplest one for our case: an exterior preprocessor. “Exterior” means that macros definitions are located outside the program being processed. We won’t add any new syntax for lambda calсulus in order to express macros in it, it would be too difficult. Macro processor is just being applied to the program and gives a blank lambda-term at the output. By the way, MOC in Qt operates the same way.
Two Stages
By this moment there was just one important event in the life of our programs, which is their value definition with the help of Eval. And now macros expanding with the help of Expand will be added. Everything given at the Eval entry should be run through Expand first. Let’s add a new Compute function which combines these actions:template struct Expand;
template
struct Compute
{
typedef typename Eval::result, Env>::value value;
}; Expand accepts one argument only. We’ll consider it as a black box: a program with macros on input and without them on output. In our case no macro environments are needed.
Macros Implementation
And now macros should be implemented inside Expand. We need Lam_ and App_, that are expanding the following way:
| Before | After |
|---|---|
| Lam_<'x', 'y', ..., 'z', B> | Lam<'x', Lam<'y', ..., Lam<'z', B>...>> |
| App_ |
App<...App |
| App_<'a', ...> | App_ |
Templates of arbitrary arity are now available in C++11, which eases the task a lot. If you are the owner of C++03 compiler, all you can do is write hundreds of specializations. Lam_2 is for two arguments, Lam_3 is for three, App_4 is for four, etc. Or you can repeat everything shown below with the help of C++ preprocessor.
Lam_
To be honest, C++11 templates have some restrictions so the syntax should be a bit adjusted. The pack of arguments can only be the last template argument, so a special “argument holder” for Lam_ should be introduced.
template struct Args;
template struct Lam_;
template
struct Expand, Exp>>
{
typedef typename Expand>::result result;
};
template
struct Expand, Exp>>
{
typedef Lam, Exp>>::result> result;
}; Pay attention to repeated Expand calls during the expanding process. They are necessary, as Expand<...>::result should always be a blank lambda-term with no macros.
App_
Also, C++11 doesn't allow to mix numbers-arguments and types-arguments in a pack. Therefore App_ will have two fitting variants. Not good.
App_s implementations (for symbols) and App_i (for types) are more extensional, so I'll explain it within this block.
At first we should unify the application arguments. They can be either a pack of variables’ names or a pack of lambda-terms. Names should be converted to terms. It would be much easier if C++11 allowed writing map for packs. But we’ll build another linked list. (Maybe it’s possible to write map? Anyone?)
struct Nil;
template struct RefList; Two more functions, which convert packs to similar lists. Each symbol from the variables names pack should be “wrapped” in Ref:
template struct ToRefList_s;
template
struct ToRefList_s
{
typedef RefList, Nil> result;
};
template
struct ToRefList_s
{
typedef RefList, typename ToRefList_s::result> result;
}; The pack of terms can be left as it is just by converting it to a list. Syntax checking and macros opening will be executed in it later.
template struct ToRefList_i;
template
struct ToRefList_i
{
typedef RefList result;
};
template
struct ToRefList_i
{
typedef RefList::result> result;
}; Now the acquired list of call arguments should be processed.
App_wrap function implements the beloved by everyone algorithm — list reversing with Prolog. But RefList is converted to App “list” when in use only. Its first argument is a collected App “list”, and the second one is the not reversed part of RefList.
The first element of RefList list should be applied to the second one. Then other elements are successively applied to this result. We stop when all elements are over (when we reach Nil).
template struct App_wrap;
template
struct App_wrap>>
{
typedef typename App_wrap, R>::result result;
};
template
struct App_wrap>
{
typedef typename App_wrap, Nil>::result result;
};
template
struct App_wrap>
{
typedef typename App_wrap, D>::result result;
};
template
struct App_wrap
{
typedef Apps result;
}; Have you noticed it? Yep, it’s a tail recursion.
In the end we write the following simple definitions. They call the functions we mentioned above which do all the dirty work. After that they run the result through Expand one more time, so that there would be no unopened macros on output.
template struct App_s;
template struct App_i;
template
struct Expand>
{
typedef typename Expand<
typename App_wrap::result
>::result
>::result result;
};
template
struct Expand>
{
typedef typename Expand<
typename App_wrap::result
>::result
>::result result;
}; The Rest
The last one, but a very important addition. The expander should accurately process the in-built language constructs by opening macros where they can be met.
template
struct Expand>
{
typedef Ref result;
};
template
struct Expand>
{
typedef Lam::result> result;
};
template
struct Expand>
{
typedef App::result,
typename Expand::result> result;
}; Noticed parallels with Eval and Apply in Expand? Well done! (Complete code with macros support.)
Recursion
Having told about Turing-completeness we didn’t mention that this system allows expressing the loops! Let’s take a look at loop calculations by the example of factorial.
You can’t directly call a recursion in lambda calculus as abstractions don’t have names.
In order to do recursion in a usual form we’ll need a magic Rec operator. It is similar to general Lam abstraction, but creates abstractions with an additional argument which is a link to the determined abstraction.
However, skillful mathematicians found a way to avoid this restriction. The so-called Y-combinator allows expressing recursive functions as solving functional equations about fixed points. You can find additional information on the subject in the Internet. Now it’s important that Y-combinator is written the following way:
// Y = λf.(λx.f (x x)) (λx.f (x x))
typedef Lam<'f', App, App_s<'x', 'x'>>>,
Lam<'x', App, App_s<'x', 'x'>>>>> Y; In order to express recursive function, which calculates factorial, at first you should define all the necessary mathematic and logic operators (multiplication, subtraction, comparison). You can find all definitions here (the last four chapters). They are standard for similar functions in lambda calculus. (If you are still reading the article, you should have no problems with understanding and implementing them.)
In the end, all the necessary definitions are bound by the appropriate symbols and packaged in StandardLibrary environment. And now we can write a generating function for the factorial:
// F = λfn.if (= n 0) 1
// (* n (f (- n 1)))
typedef Lam_,
App_i, App_s<'=', 'n', '0'>,
Ref<'1'>,
App_i, Ref<'n'>,
App_i, App_s<'-', 'n', '1'>>> > > Fact_gen; It differs from the general unary by accepting an additional f argument, which is a function of factorial calculation (general now). The role of Y-combinator lies in define such Fact function by a Fact_gen generating function. So that App
Okay, let’s try to apply all of it together, having calculated (Y F 1) — one factorial
/* ... */
#include
int main()
{
/* Y and Fact_gen */
typedef Compute,
App_i >,
StandardLibrary>::value Result;
std::cout << Result::interpretation;
} ilammy@ferocity ~/dev/tlc $ g++ -std=c++11 lc.cpp 2>&1 | wc -c
64596It doesn’t compile. And we have 64Kb of errors in a log. Why?
It’s all about calculations order. A general Y-combinator is recorded on the basis of a normal calculation order. In which f (x x) will at first call (x x) substitute f to the body and after that only, if needed, (x x) value will be calculated (with a lazy substitute as well).
In case of applicative order (call by value) this clause is calculated right away. This will obviously lead to an endless loop (if we look what x argument should be equal to). For example, the mentioned above interpreter of lambda calculus on Scheme, loops.
Looking through the gcc log, we’ll see that
struct Apply<
Closure<
Lam<'x', App, App, Ref<'x'>>>>,
Bind<'f',
Closure,
StandardLibrary > >,
Closure<
Lam<'x', App, App, Ref<'x'>>>>,
Bind<'f',
Closure,
StandardLibrary > > > doesn’t define result, so this call has no sense. The compiler saw and broke an endless loop of template substitute, which is undefined by standards (14.7.1/15).
C++ templates carry out calculations in the applicative order, as typename Eval
Z-combinator should be used in the languages with applicative order of calculations. It’s a modification of Y-combinator, where (x x) clause is “wrapped” into abstraction. This prevents its early calculation:
// Z = λf.(λx.f (λy.x x y)) (λx.f (λy.x x y))
typedef Lam<'f', App, Lam<'y', App_s<'x', 'x', 'y'>>>>,
Lam<'x', App, Lam<'y', App_s<'x', 'x', 'y'>>>>>> Z; Now we can’t see any compilation errors as well as its end. We have obviously outwitted the compiler this time and made it to endlessly and recursively open something. Of course it can only be a recursive call of factorial.
Wait! Then when the compiler should stop substituting factorial into itself? When do we want it to stop? I guess, If operator is responsible for that: when the factorial argument is 0, 1 should be returned, and recursive call shouldn’t be made. How is If defined?
typedef Lam_, App_s<'c', 't', 'f'>> If; As an abstraction. It seems to be good, a standard definition for boolean Church constants… But it’s meant for the normal reduction order! In case of applicative order If calculates both branches at once with a condition, and makes the choice after that only.
The problem can be solved in an analogous to Z-combinator way. Wrap the delayed calculations into abstraction. But in case with the If the condition shouldn’t be wrapped. So, unfortunately, If can not be a handy function in applicative languages. But we can make it a macro!
template struct If;
template
struct Expand>
{
typedef typename Expand<
App_i,
Lam<'u', Else>,
Lam<'u', Ref<'u'>> >
>::result result;
}; 'u' variable shouldn’t concur with any free Then or Else variable. Our macro system doesn’t have such feature. We have quite a limited number of variables’ names. So we’ll reserve 0 identifies as non-concurring with anything.
template
struct Lookup;
template
struct Lookup<0, Env>;
template
struct Lookup>
{
typedef Val result;
}; Our factorial will finally operate. (github code)
ilammy@ferocity ~/dev/tlc $ time g++ -std=c++11 lc.cpp -DARG=6
real 0m12.630s
user 0m11.979s
sys 0m0.466s
ilammy@ferocity ~/dev/tlc $ ./a.out
720Unfortunately, I didn’t manage to wait for seven factorial calculation, not to mention the fact that compiler simply dies on 32-bit systems due to stack overflow. But still…

Conclusion
I guess, this interpreter is of no practical engineer use, but the idea itself is great. C++ templates — it’s from “incidentally Turing-complete” things in theoretical informatics. I had a similar feeling when I found out that the subsystem of page memory of x86 processors control is also Turing complete. While this interpreter allows carrying out calculations without executing any C++ operator, MMU allows carrying out calculations without executing any machine instruction of a program.
Unfortunately, for the moment I’ve read DCPL till chapter 8. So writing an interpreter of a typed lambda calculus is left for the readers as an exercise. My mathematic grounding is too weak for it.
P.S. All the time writing this post, I couldn’t but think: “It’s either already in the Boost, or can be written there in three lines”.
[original source]
0 comments
Upload image