To begin with, I would like to thank you for a warm welcome of Lock-free Data Structures. 1 — Introduction. I can see that lock-free topic is interesting and it makes me glad. I planned to build a series according to academic concept, flowing from basics to algorithms, at the same time illustrating the text with the code from libcds. But part of the readers wants me to show them, without any delays and rambling on, how to use the library. I agree that there is some reason in it. After all, it’s not interesting for me either to know what is inside the boost, — and how to apply it! So I will divide my epic series into three parts: Basics, Inside and From Outside. Each article of the epic will refer to one of the parts. In the Basics I will tell about the low-level things, even about modern CPUs build. This part is for the whyers like me. In the Inside part I will cover interesting algorithms and methods of the lock-free world – it’s more likely a theory about how to implement a lock-free data structure. Libcds will be an endless source of the C++ code. From Outside will contain articles on libcds implementation practice, — programming solutions, advice and FAQ. From Outside is fed by the readers’ questions, comment, offers.
This article is not so much about C++ (though about it as well) and not even about the lock-free (though without atomic lock-free algorithms are invalid), but about atomic primitives implementation in the modern processors and about basic problems that arise when using such primitives.
Atomicity — is the first
Atomic operations are divided into simple — read and write — and operations of atomic change (read-modify-write, RMW). Atomic operation can be defined as an indivisible operation. It has either occurred or not, we can not see any intermediate stages of its execution, no partial effects. So even simple read/write operations can be not atomic. For example, reading of not aligned data is non-atomic. In x86 architecture such reading will lead to the internal avoidance that will make processor read data in parts. In other architectures (Sparc, Intel Itanium) it will lead to segmentation fault that can be intercepted and processed, but atomicity is out of question in this case. In modern processors atomicity of read/write is only guaranteed of aligned integral types (integer numbers and pointers). A modern compiler guarantees correct alignment of volatile fundamental types. If you want to work with the structure atomically (of 4-8 bites size), you should care yourself about the correct alignment with the help of compiler directives (attributes). Each compiler supports its own unique method of indicating data/types alignment. By the way, libcds library supports a set of backup types and macros, which hide the compiler-dependent part when declaring aligned data.
Compare-and-swap
It’s quite difficult, if possible at all, to contrive an algorithm of a lock-free container, which uses read/ write only (I don’t know such data structures for a random number of threads). That’s why developers of processors architectures have applied RMW-operations, which can atomically perform the reading of the aligned cell and writing into it: compare-and-swap (CAS), fetch-and-add (FAA), test-and-set (TAS) etc. In the academic community compare-and-swap (CAS) operation is considered the basic one. Its pseudo code is the following:
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
else
return false ;
}In words: if the current value of the variable at pAddr address equals the expected one nExpected, then set the variable's value to the value of nNew and return true, otherwise return false, the variable value doesn’t change. All of it is carried out atomically, indivisibly and without any evident partial effects. With the help of CAS all other RMW-operations can be evaluated. For example, fetch-and-add will look like the following:
int FAA( int * pAddr, int nIncr )
{
int ncur ;
do {
ncur = *pAddr ;
} while ( !CAS( pAddr, ncur, ncur + nIncr ) ;
return ncur ;
}”The academic” variant of CAS operation is not always handy in practice. Often, when CAS fails, we wonder what the current value of the cell is. Therefore another variant of CAS is often considered (the so-called valued CAS, carried out atomically as well):
int CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return nExpected ;
}
else
return *pAddr
}The compare_exchange function in C++11 covers both variants (strictly speaking, there’s no such function in C++11, there are its variants compare_exchange_strong and compare_exchange_weak, but I will tell about them later):
bool compare_exchange( int volatile * pAddr, int& nExpected, int nNew );nExpected argument is being passed by reference and contains the expected variable value at pAddr address (on input). On output — the value before the change. The function returns the sign of success: true, if there is nExpected value at address (it’s changed to nNew in this case), false in case of fail (nExpected will contain the current variable value at address pAddr). Such a multipurpose CAS operation build covers both variants of the “academic” CAS definition. But in practice compare_exchange applying involves mistakes, as you should keep in mind that nExpected argument is passed by reference and can be changed, which is not always acceptable.
By using compare_exchange the fetch-and-add primitive, shown above, can be written in the following way:
int FAA( int * pAddr, int nIncr )
{
int ncur = *pAddr;
do {} while ( !compare_exchange( pAddr, ncur, ncur + nIncr ) ;
return ncur ;
}ABA-problem
CAS primitive is good in many ways, but a serious problem can arise by applying it. It is called an ABA-problem. In order to describe it, a typical pattern of CAS operation usage should be considered:
int nCur = *pAddr ;
while (true) {
int nNew = calculating new value
if ( compare_exchange( pAddr, nCur, nNew ))
break;
}In fact, we “reside” in the loop until CAS works. The loop is required, as between the reading the current variable value at pAddr address and calculating new value, nNew the variable at pAddr address can be changed by another thread.

ABA-problem can be described in the following way. Suppose, X thread reads A value from some shared cell that has a pointer to some data. Then another Y thread changes this cell value to B and then to A again. But now A pointer points to some other data. When the X thread via CAS primitive tries to change the cell value, the pointer comparison with the previous (read) one value A is successful and CAS result is successful as well. But now A points to absolutely different data! As a result, the thread can break internal object connections, (which, in its turn, can lead to failure).
Here’s the implementation of the lock-free stack, confirmed of ABA-problem [Mic04]:
// Shared variables
static NodeType * Top = NULL; // Initially null
Push(NodeType * node) {
do {
/*Push1*/ NodeType * t = Top;
/*Push2*/ node->Next = t;
/*Push3*/ } while ( !CAS(&Top,t,node) );
}
NodeType * Pop() {
Node * next ;
do {
/*Pop1*/ NodeType * t = Top;
/*Pop2*/ if ( t == null )
/*Pop3*/ return null;
/*Pop4*/ next = t->Next;
/*Pop5*/ } while ( !CAS(&Top,t,next) );
/*Pop6*/ return t;
}The following sequence of actions leads to the stack structure break (Please note, that this sequence isn’t the only one that illustrates ABA-problem).
| Thread X | Thread Y |
|---|---|
| Calls Pop(). Line Pop4 is performed, variables values: t == A next == A->next |
|
| NodeType * pTop = Pop() pTop == top of the stack, i.e. A Pop() Push( pTop ) Now the top of the stack is A again Note, that A->next has changed |
|
| Pop5 line is being performed. CAS is successful, but the field Top->next is assigned with another value, which doesn’t exist in the stack, as Y thread has pushed A and A->next out, of a stack and the local variable next has the old value of A->next |
ABA-problem is a scourge of all lock-free containers based on CAS primitive. It can arise in a multithreaded code only as a result of element A deletion from the container and its change to another one (B), and then to A again (thus the name is ABA-problem). While another thread keeps the pointer to an element, which is currently being deleted. Even if the thread physically deletes A (delete A), and then calls new to create a new element, there are no guarantees that the allocator doesn’t return address of A (good allocators would do so). The problem often touches more than two threads. In this regard we can talk of ABCBA-problem, ABABA-problem, etc. as long as you can).
In order to get rid of ABA-problem you should physically delete (deferred deallocation, or safe memory reclamation) the element at the moment when there is a guarantee that none of competitive threads has either local, or global references to the deleted element.
Thus, element deletion from the lock-free structure consists of two stages:
- The first stage – element exclusion from the lock-free container;
- The second stage (deferred) – physical removal of the element when there are no links to it.
I will dwell on different schemes of deferred deletion in one of the following articles.
Load-Linked / Store-Conditional
I guess ABA-problem presence at CAS using has pushed processors developers to search for other RMW-operations that aren’t affected by the ABA-problem. And such operations have been found — load-linked/store-conditional (LL/SC) pair. These operations are very simple, here’s their pseudo code:
word LL( word * pAddr ) {
return *pAddr ;
}
bool SC( word * pAddr, word New ) {
if ( data in pAddr has not been changed since the LL call) {
*pAddr = New ;
return true ;
}
else
return false ;
}LL/SC Pair works as bracket operators. Load-linked (LL) operation simply returns current variable value at pAddr address. Store-conditional (SC) operation performs saving to earlier read by LL operation pAddr address only in case if the data in pAddr have not changed since reading. Under the change is understood any modification of the cache-line, to which pAddr address refers. In order to implement LL/SC pair the developers had to change the cache structure. Roughly speaking, each cache-line must have an additional status bit. This bit is linked when read by LL operation. The bit is reseted when any writing to the cache-line is made and before saving the SC operation checks whether the given bit is specified in the cache-line. If bit = 1, meaning that no one has changed the cache-line, the value at pAddr address changes to the new one and SC operation is successful. Otherwise the operation fails. The value at pAddr address doesn’t change to the new one.
CAS primitive can be implemented via LL/SC pair as follows:
bool CAS( word * pAddr, word nExpected, word nNew ) {
if ( LL( pAddr ) == nExpected )
return SC( pAddr, nNew ) ;
return false ;
}Please note that despite the multi stages of this code it performs atomic CAS. Content of the target memory cell either doesn’t change, or changes atomically. LL/SC pair implementation in architectures, that support CAS primitive only, is possible, but not that primitive. I am not going to describe it here. If you are interested, please refer to the article [Mic04].
Modern processor architectures are divided into two big parts. The first one supports CAS-primitive in its computer code, the second one — LL/SC pair. CAS is implemented in x86, Intel Itanium, Sparc architectures. For the first time primitive appeared in IBM System 370 primitive. LL/SC pair – in PowerPC, MIPS, Alpha, ARM architectures, DEC is suggested for the first time. It’s worth noting that LL/SC primitive isn’t perfectly implemented in modern architectures. For example, you can’t make nested LL/SC calls with different addresses, false discards of linked flag possible (the so-called false sharing, see below); there’s no flag validation inside the LL/SC pair.
From the point of C++ view, C++11 doesn’t consider LL/SC pair, it just describes the atomic primitive compare_exchange (CAS) and derived from it atomic primitives – fetch_add, fetch_sub, exchange etc. The standard means that it’s quite simple to implement CAS via LL/SC. But backward implementation – LL/SC via CAS – isn’t trivial at all. So, in order not to complicate life of C++ library developers, Standardization Committee introduced in C++ compare_exchange only. This is enough for lock-free algorithms implementation.
False sharing
In modern processors cache-line length (L) is 64 – 128 bytes and has a tendency to increase in new models. Data exchange between the primary storage and the cache is carried out in blocks of L byte (usually L is power of two). Even if one byte in the cache-line changes, all the line is considered invalid and requires synchronization with the primary storage. It’s managed by the cache-coherent protocol in multiprocessor/multi core architecture.
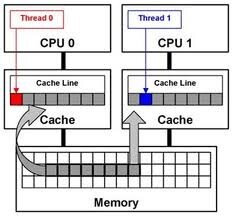
If different shared data get into one cache-line (located in adjacent addresses), the change of one data leads, from processor’s view, to invalidation of other data, that are in the same cache-line. This situation is called false sharing. For LL/SC primitives false sharing is destructive. Implementation of these primitives is performed in terms of the cache-lines. Load-Linked operation links the cache-line. Store-Conditional operation checks before writing, whether the link flag for this line is reseted. If the flag is reseted, write isn't performed and SC returns false. As the cache-line length L is quite long, false failure of SC primitive happens in case of any cache-line change, which is not connected with the target data. As a result we can get a livelock: a situation when processors/cores are 100% loaded, but there’s no progress.
In order to get rid of false sharing, each shared-variable must completely take the cache-line; padding is usually used for it.
struct Foo {
int volatile nShared1;
char _padding1[64]; // padding for cache line=64 byte
int volatile nShared2;
char _padding2[64]; // padding for cache line=64 byte
};The physical structure of the cash influences all the operations (including CAS), not LL/SC primitives only. In some works are studied data structures that are build in special way taking into account cache structures (cache-line length mainly). Capability can increase a lot when the data structure is properly built (“for cache”).
CAS Variations
I will also like to cover two more useful primitives — double-word CAS (dwCAS) and double CAS (DCAS).
Double-word CAS is similar to general CAS, but it operates on the double sized cell: 64-bit for 32-bit architectures and 128-bit (at least 96-bit) for 64-bit. For the architectures that provide LL/SC instead of CAS, LL/SC should also operate on double-words. I know x86 only, which supports dwCAS. So why is this primitive so useful? It allows organizing one of the first ABA-problem solution schemes (porposed by IBM) — tagged pointers. The scheme lies in correlating each shared tag pointer – integer. Tagged pointer can be described by the following structure:
template
struct tagged_pointer {
T * ptr ;
uintptr_t tag ;
tagged_pointer()
: ptr( new T )
, tag( 1 )
{}
}; In order to provide atomicity, variables of this type should be aligned on the double-word: 8 bytes for 32-bit architectures and 16 bytes for 64-bit. The tag contains the “version number” data, at which ptr points to. I will dwell on tagged pointers in one of the following articles, which will concentrate on safe memory reclamation and SMR. For now I will just mention the fact that memory, once dedicated to T-type data (and corresponding tagged_pointer), should not be physically deleted. It should be moved to the free-list (separate for each T-type), from which the data will be distributed in future with tag incrementing. That’s what allows ABA-problem solution: practically the pointer is complex and contains a version number in the tag (position number of distribution). If the pointers of tagged_pointer type are equal within the dwCAS arguments, but tags values are different, then dwCAS will not be successful in this case.
The second atomic primitive – double CAS (DCAS) – is purely theoretic and isn’t implemented in any of modern processor architectures. The pseudo code of DCAS is the following:
bool DCAS( int * pAddr1, int nExpected1, int nNew1,
int * pAddr2, int nExpected2, int nNew2 )
atomically {
if ( *pAddr1 == nExpected1 && *pAddr2 == nExpected2 ) {
*pAddr1 = nNew1 ;
*pAddr2 = nNew2 ;
return true ;
}
else
return false
}DCAS operates on two random aligned memory cells and changes value of both of them, if current values concur with the expected ones.
Why is this primitive so interesting? The thing is, it’s quite easy to build a lock-free double-linked list (deque). This data structure is basis for many interesting algorithms. There are plenty of “academic” works that concentrated on data structures, based on DCAS. Though this primitive hasn’t been implemented in the hardware, there are some works (e.g. [Fra03] – the most popular) describing algorithm of DCAS building (and multi-CAS for any amount of pAddr1 … pAddrN addresses) on the basis of general CAS.
Performance
So what about atomic primitives’ performance?
Modern processors are so complicated and unpredictable that developers don’t give duration guarantees for instructions. Especially for atomic ones, in the work of which internal synchronization is involved, processor buses signaling, etc. There are plenty of works, the authors of which are trying to measure processor instructions length. I will mention measures from [McKen05]. In this work the authors, among other things, compare the length of atomic increment and CAS primitive with the nop (no-operation) length. Thus, for Intel Xeon 3.06 hHz (2005 model) atomic increment has the length of 400 nop, CAS – 850 – 1000 nop. The Processor IBM Power4 1.45 hHz: 180 nop for atomic increment and 250 nop for CAS. The measures are quite old, processor architecture has made several steps forward since then, but the order of figures is the same, I guess.
As you can see, atomic primitives are quite complex. So applying them everywhere is quite disadvantageous. For example, if a binary-tree search algorithm uses CAS to read the current tree node, I have a dim view of such algorithm (and I’ve seen them). It’s worth noting that with each new Intel Core architecture generation CAS becomes faster. Apparently, Intel engineers made a lot of efforts to improve micro architectures.
Volatile and Atomacity
There is a mysterious keyword volatile in C++. Sometimes volatile is associated with atomicity and regulation. It’s wrong, but has some historic grounds.
Volatile does only guarantee that the compiler won’t cache value in the register (optimizing compilers often do so: the more registers, the more they cache). Reading the volatile-variable always means reading from memory, volatile-variable writing – always writing to memory. So if anyone will concurrently change volatile-data, we will always notice that.
Actually, we won’t. Due to lack of memory barriers. In some languages (Java, C#) volatile is assigned with a magic status providing the regulation, but not in C++11. Volatile doesn’t guarantee any special regulation. And now we know that appropriate regulation is the necessary condition for atomicity.
Thus, it’s unnecessary to indicate volatile for atomic variable in C++11 compatible compiler. But for old compiler it’s sometimes necessary, if you implement atomic by yourself. In the following declaration:
class atomic_int {
int m_nAtomic;
//….
};Compiler has every right to “optimize” the call to m_nAtomic (despite the fact that the call is indirect, via this). Therefore sometimes it’s useful to state here int volatile m_nAtomic.
libcds
So what have we got in libcds library? We have atomic primitives implementation in the manner of C++11 for x86/amd64, Intel Itanium и Sparc architectures. If the compiler doesn’t support C++11 (supports his newest versions only – available ones are GCC 4.7+, MS Visual C++ 2012, Clang 3.0+), libcds uses its own implementation of atomic primitives. The main basic primitive when building lock-free data structures, besides common atomic write/read, is CAS. DwCAS is rarely used. For now there is no DCAS (and multi-CAS) implementation in libcds, but it’s quite possible that it will appear in future. The only fact that stops is that according to many researches DCAS implementation by [Fra03] algorithm is quite inefficient. But I have already mentioned that efficiency criterion is highly individual in the lock-free world. What is inefficient now, for this hardware and for this task, can be extremely efficient later for a different hardware and different task!
In the following article of Basics I will dwell on memory ordering and memory barrier (memory fence).
The links:
[Cha05] Dean Chandler Reduce False Sharing in .NET, 2005, Intel Corporation
[Fra03] Keir Fraser Practical Lock Freedom, 2004; technical report is based on a dissertation submitted September 2003 by K.Fraser for the degree of Doctor of Philosophy to the University of Cambridge, King's College
[McKen05] Paul McKenney, Thomas Hart, Jonathan Walpole Practical Concerns for Scalable Synchronization
[Mic04] Maged Michael ABA Prevention using single-word instruction, IBM Research Report, 2004
Link to Part 1: Lock-free Data Structures. 1 — Introduction
2 comments
But why would we use 60 bytes for padding?
Upload image