I’ll review the embedded into OS implementation of the lock-free stack and its performance comparison with the cross-platform analogues.
The implementation of non-blocking stack on the basis of a singly linked list (Interlocked Singly Linked Lists, SList), has been available in WinAPI for quite a while. Operations on such list initializing and stack primitives over it have been implemented. Without going into details of implementing the SLists, the Microsoft just say that they use some non-blocking algorithm in order to implement atomic synchronization, increase performance and get rid of lock problems.
You can implement non-blocking singly linked lists by yourself. There are some articles written on the topic.
But there have been no 128-bit CAS operation before Windows 8. This fact caused problems when implementing such algorithms in 64-bit applications. SList helps to solve this task.
Implementation
Memory Alignment Requirement for the list elements by MEMORY_ALLOCATION_ALIGNMENT boundary is one of the SList implementation peculiarities. Similar requirements are specified for other interlocked operations in WinAPI. It means that we should use aligned_malloc/aligned_free when working with the memory of list elements.Another peculiarity is requiring to place the pointer to the next list element of SLIST_ENTRY type at the very beginning of the structure: before our own fields.
The following is the implementation of a template on C++ that converts native WinAPI functions for the work with SList:
template
class SList
{
public:
SList()
{
// Let Windows initialize an SList head
m_stack_head = (PSLIST_HEADER)_aligned_malloc(sizeof(SLIST_HEADER),
MEMORY_ALLOCATION_ALIGNMENT);
InitializeSListHead(m_stack_head); //UPD: 22.05.2014, thx to @gridem
}
~SList()
{
clear();
_aligned_free(m_stack_head);
}
bool push(const T& obj)
{
// Allocate an SList node
node* pNode = alloc_node();
if (!pNode)
return false;
// Call the object's copy constructor
init_obj(&pNode->m_obj, obj);
// Push the node into the stack
InterlockedPushEntrySList(m_stack_head, &pNode->m_slist_entry);
return true;
}
bool pop(T& obj)
{
// Pop an SList node from the stack
node* pNode = (node*)InterlockedPopEntrySList(m_stack_head);
if (!pNode)
return false;
// Retrieve the node's data
obj = pNode->m_obj;
// Call the destructor
free_obj(&pNode->m_obj);
// Free the node's memory
free_node(pNode);
return true;
}
void clear()
{
for (;;)
{
// Pop every SList node from the stack
node* pNode = (node*)InterlockedPopEntrySList(m_stack_head);
if (!pNode)
break;
// Call the destructor
free_obj(&pNode->m_obj);
// Free the node's memory
free_node(pNode);
}
}
private:
PSLIST_HEADER m_stack_head;
struct node
{
// The SList entry must be the first field
SLIST_ENTRY m_slist_entry;
// User type follows
T m_obj;
};
node* alloc_node()
{
return (node*)_aligned_malloc(sizeof(node), MEMORY_ALLOCATION_ALIGNMENT);
}
void free_node(node* pNode)
{
_aligned_free(pNode);
}
T* init_obj(T* p, const T& init)
{
return new (static_cast(p)) T(init);
}
void free_obj(T* p)
{
p->~T();
}
}; Performance Test
To verify the algorithm we used a standard test utilizing «producers» and «consumers». We also varied the number of consumer and producer threads each test run, including the size of the total thread population (producers + consumers). Each «producer» always creates the same amount (1 million) of tasks(iterations). Therefore When the number of producer type threads is N, the total amount of tasks is N*1M.SList Test Code
class test
{
private:
static UMS::SList stack;
public:
static const char* get_name() { return "MS SList"; }
static void producer(void)
{
for (int i = 0; i != iterations; ++i)
{
if (!stack.push(++producer_count))
return;
}
}
static void consumer(void)
{
int64_t value;
while (WaitForSingleObject(hEvtDone, 10) != WAIT_OBJECT_0)
{
while (stack.pop(value))
{
++consumer_count;
}
}
while (stack.pop(value))
{
++consumer_count;
}
}
}; To prevent consumer threads from running free and freezing in sleep we used Windows synchronization objects of Event type. Thus consumers could clear the stack after producers had finished their work. Consumers start concurrently with producers. They already have taken some part of the stack tasks by the moment producers stop and hEvtDone action is enabled.
Below is the function calling our test with the necessary number of threads:
template
void run_test(int producers, // Number of producer threads
int consumers // Number of consumer threads
)
{
using namespace std;
boost::thread_group producer_threads, consumer_threads;
// Initiate a timer to measure performance
boost::timer::cpu_timer timer;
cout (nanoseconds);
auto time_per_item = nanoseconds.count() / producer_count;
cout The test had been run by the following conditions:
- OS: Windows 8 64-bit
- CPU: 4x Intel Core i7-3667U @ 2.00GHz
- RAM: 8GB
- Compiler: Microsoft ® C/C++ Optimizing Compiler Version 18.00.21005.1
- Configuration: Release, Static Runtime(/MT), Optimize Speed (/Ox), x64 Architecture
- boost:1.55 version
- libcds:1.5.0 version
 Parameters variations for two measurements (consumers, producers) provide us with t(p, c) function, the chart of which is shown at the image above.
Parameters variations for two measurements (consumers, producers) provide us with t(p, c) function, the chart of which is shown at the image above.So that we wouldn’t have to count the number of zeros in results with our eyes, we provide the time for one task execution in nanoseconds instead of counting the number of tasks per second. The time is calculated as the total test time divided by the total number of tasks. The lower this amount is, the faster the algorithm operation.
The number of threads of each type changed by the succession:
int NumThreads[] = { 2, 4, 8, 12, 16, 20, 24, 32, 36, 48, 56, 64, 72 };Pay attention to this surface. You can notice the algorithm speedup with low consumer count (the chart area painted green). Further increase of both types’ threads doesn’t lead to obvious change of operation speed. Though it’s obvious that the pointer “floats” a bit in a narrow corridor, but the chart keeps the calming orange color.
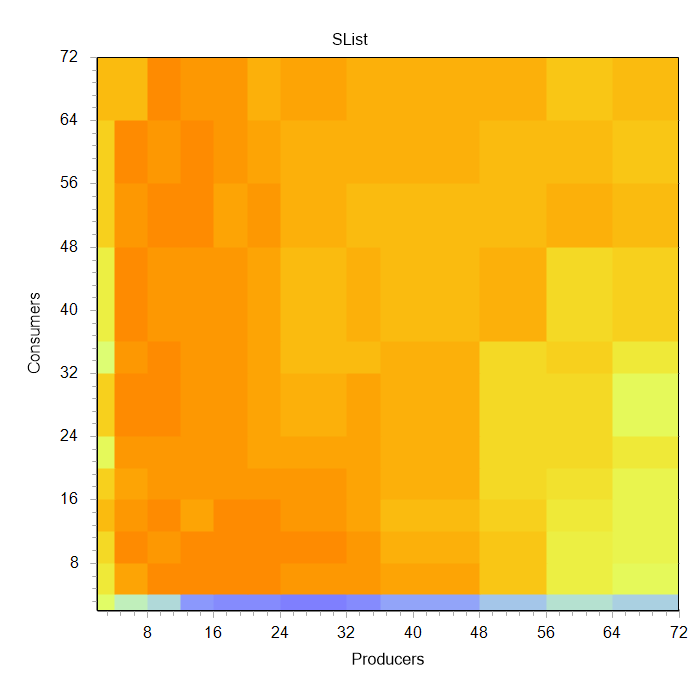
If we take a look at the same chart in a bit different execution this boundary is more distinct. At the image on the right a beneficial green and blue zone is quite distinguishable. It marks the entire region with four consumers and random number of producers. It concurs with the number of kernels in the experiment.
Then I’ll show that other implementations demonstrate similar dynamics. It makes the algorithm used by the Microsoft similar with the one applied in third-party libraries.
It’s pleasant to see that lock-free approach is as large as life here. It’s hard to imagine 72(+72) threads, each containing 1 million tasks, hanging in the lock. But articles about lock-free usually begin exactly with that.
Comparison
An identical test has also been started at the same computer for two other implementations of non-blocking containers taken from the popular libraries (boost::lockfree and libcds) in the following loop:int NumThreads[] = { 2, 4, 8, 12, 16, 20, 24, 32, 36, 48, 56, 64, 72 };
for (int p : NumThreads)
for (int c : NumThreads)
{
run_test<:boost::test>(p, c);
run_test<:slist::test>(p, c);
run_test<:libcds::test>(p, c);
}Despite some similarity of implementations, below are tests run for these libraries and results of their every work.
Boost.Lockfree Library
This library has been introduced quite recently. There are three containers: a queue, a stack and a ring buffer. It’s handy to use their classes, as always. There’s also documentation and even examples.Below is the code for the similar test using boost::stack.
class test
{
private:
static ::boost::lockfree::stack stack;
public:
static const char* get_name() { return "boost::lockfree"; }
static void producer(void)
{
for (int i = 0; i != iterations; ++i)
{
while (!stack.push(++producer_count));
}
}
static void consumer(void)
{
int64_t value;
while (WaitForSingleObject(hEvtDone, 10)!=WAIT_OBJECT_0)
{
while (stack.pop(value))
{
++consumer_count;
}
}
while (stack.pop(value))
{
++consumer_count;
}
}
}; Providing the test results as charts:
Libcds Library
Despite its consumer qualities, this library seemed a bit bulky and ill-documented.Besides, in every thread using their lock-free containers it’s required to execute attach of your own thread to their engine (perhaps, due to TLS?), then detach it. It’s also necessary to initialize the Hazard Pointer singleton.
It’s difficult to call this library beautiful, despite the enormous number of implemented lock-free containers fitting any taste. You’ll have to get used to it.
The following is the code for the similar test using cds::container::TreiberStack:
class xxxstack : public cds::container::TreiberStack<:gc::hp int64_t>
{
public:
cds::gc::HP hzpGC;
xxxstack()
{
cds::Initialize(0);
}
};
class test
{
private:
static xxxstack stack;
public:
static const char* get_name() { return "libcds tb"; }
static void producer(void)
{
// Attach the thread to libcds infrastructure
cds::threading::Manager::attachThread();
for (int i = 0; i != iterations; ++i)
{
//int value = ++producer_count;
while (!stack.push(++producer_count));
}
// Detach thread when terminating
cds::threading::Manager::detachThread();
}
static void consumer(void)
{
// Attach the thread to libcds infrastructure
cds::threading::Manager::attachThread();
int64_t value;
while (WaitForSingleObject(hEvtDone, 10) != WAIT_OBJECT_0)
{
while (stack.pop(value))
{
++consumer_count;
}
}
while (stack.pop(value))
{
++consumer_count;
}
// Detach thread when terminating
cds::threading::Manager::detachThread();
}
}; Providing results of the test in the form of charts:
Performance Comparison
Despite the fact that SList is a native decision and two others are “almost” cross-platform, we think that the provided below comparison is competent. All the tests have been run under the same conditions. They demonstrate the libraries behavior under these conditions. The linear growth of tasks compounded by a growing number of threads results in an execution duration that can be painfully long.
The linear growth of tasks compounded by a growing number of threads results in an execution duration that can be painfully long.Three passes have been executed in order to stabilize the result. So the above results are average between the three runs.
You can see at the three-dimensional charts above that the diagonal (arguments values {p=c}) almost looks like a straight line. So we made extracts of results by this criterion to create a vivid comparison of three libraries.
On the right you can see what we’ve got.
It’s obvious that boost loses out to the two remaining implementations, though it demonstrates a great stability to the change of input parameters.
Implementations on libcds and SList don’t differ that much, but during the entire input interval.
Mutex Test
Let's also take a regular std::stack the access to which would be blocked by a regular std::mutex.class test
{
private:
static std::stack stack;
static std::mutex lock;
public:
static const char* get_name() { return "mutex"; }
static void producer(void)
{
for (int i = 0; i != iterations; ++i)
{
lock.lock();
stack.push(++producer_count);
lock.unlock();
}
}
static void consumer(void)
{
int64_t value;
while (WaitForSingleObject(hEvtDone, 10) != WAIT_OBJECT_0)
{
lock.lock();
if (!stack.empty())
{
value = stack.top();
stack.pop();
++consumer_count;
}
lock.unlock();
}
bool isEmpty = false;
while (!isEmpty)
{
lock.lock();
if (!(isEmpty = stack.empty()))
{
value = stack.top();
stack.pop();
++consumer_count;
}
lock.unlock();
}
}
}; We had to wait for a very, very long time. We reduced the number of tasks per thread from 1 million to 100K, which led to not so accurate results (but it isn’t necessary with such numbers). We also changed the set for the input threads number to reduce the number of points for calculation.
int NumThreads[] = { 2, 4, 8, 16, 32, 64};The results:
The result is quite significant. When there are more than 4 threads of any type the potential grows significantly. It’s difficult to add such line to the chart of the first three ones. I guess it will be better to use logarithmic graph.
Summary
It’s fair to admit that this time the Microsoft has created quite a good implementation (though of one container only), which can successfully compete with algorithms from the famous libraries. Despite the fact that the described implementation isn’t cross-platform it can be useful for developers of Windows applications.You can download the archive with the sourcecode of Visual Studio project here.
References
MSDN description of slistboost.lockfree library
libcds library
Information about SList details
0 comments
Upload image